This week, we will revisit the difference-in-differences framework and build upon it. Last week, our focus was on two groups: a treatment group and a control group. However, in real-world applications, you often encounter situations where units are treated at different times, resulting in multiple groups or cohorts. A substantial and recent body of literature has examined the so-called “staggered treatment adoption” and demonstrated that the standard estimator we used last week (two-way fixed effects, TWFE) is biased unless we account for treatment effect heterogeneity. Additionally, we must still adhere to the other assumptions relevant to the basic case, particularly parallel trends and no anticipation.
Consequently, when we observe units \(i\) across time periods \(t = 1,...,T_t\) and units adopt the binary treatment at different dates \(G_i \in (1, ..., T_t) \cup \infty\), we can extend parallel trends assumption by:
Put differently, in absence of treatment, the average outcomes by cohort would be parallel. The interpretation of the parallel trends assumption does not change, the treatment must not have any effect on the cohort before being administered.
Assumption (A.stna) “No Anticipation”
\(\mathbb{E}[Y_{i,t}(g) - Y_{i,t}(\infty) | T_i=1] = 0 \quad\) or \(\quad Y_{i,t}(g) = Y_{i,t}(\infty) \quad \forall t < g\)
Practical example
Imagine you are working as an analyst for a streaming company. Over several weeks, you have introduced unskippable ads to boost ad revenue. However, you suspect that this change may have caused some customers to watch less content. Your task is to take the data and measure the impact of unskippable ads on customer viewing behavior.
This week, we’ll tackle a more realistic scenario compared to previous weeks. Instead of having all the details about your data upfront, you’ll be given the data and will need to uncover the details as you go.
Task 1: Answer the following questions:
How many periods did we observe?
How many units did we observe?
How many cohorts/treatment groups are in the data?
How many units are in each cohort?
How many treated, not-yet treated and untreated/never treated periods did we observe?
# Task 1: Answer the following questions:# - How many periods?unique(stream$time)
# - How many treated, not-yet treated and untreated/never treated periods# do we observe?# First add treatment and relative treatment indicatorstream<-stream|># create time-variant treatment indicator D_itmutate(d_it =case_when(group==0~0,time>=group~1, .default =0))|># create relative event-time indicator D_it_kmutate(d_it_k =case_when(group==0~Inf, .default =time-group))
# Then group by treatment indicator to retrieve informationunits_d<-stream|>group_by(group, d_it)|>summarise(n_unit =n_distinct(unit))|>ungroup()print(units_d)
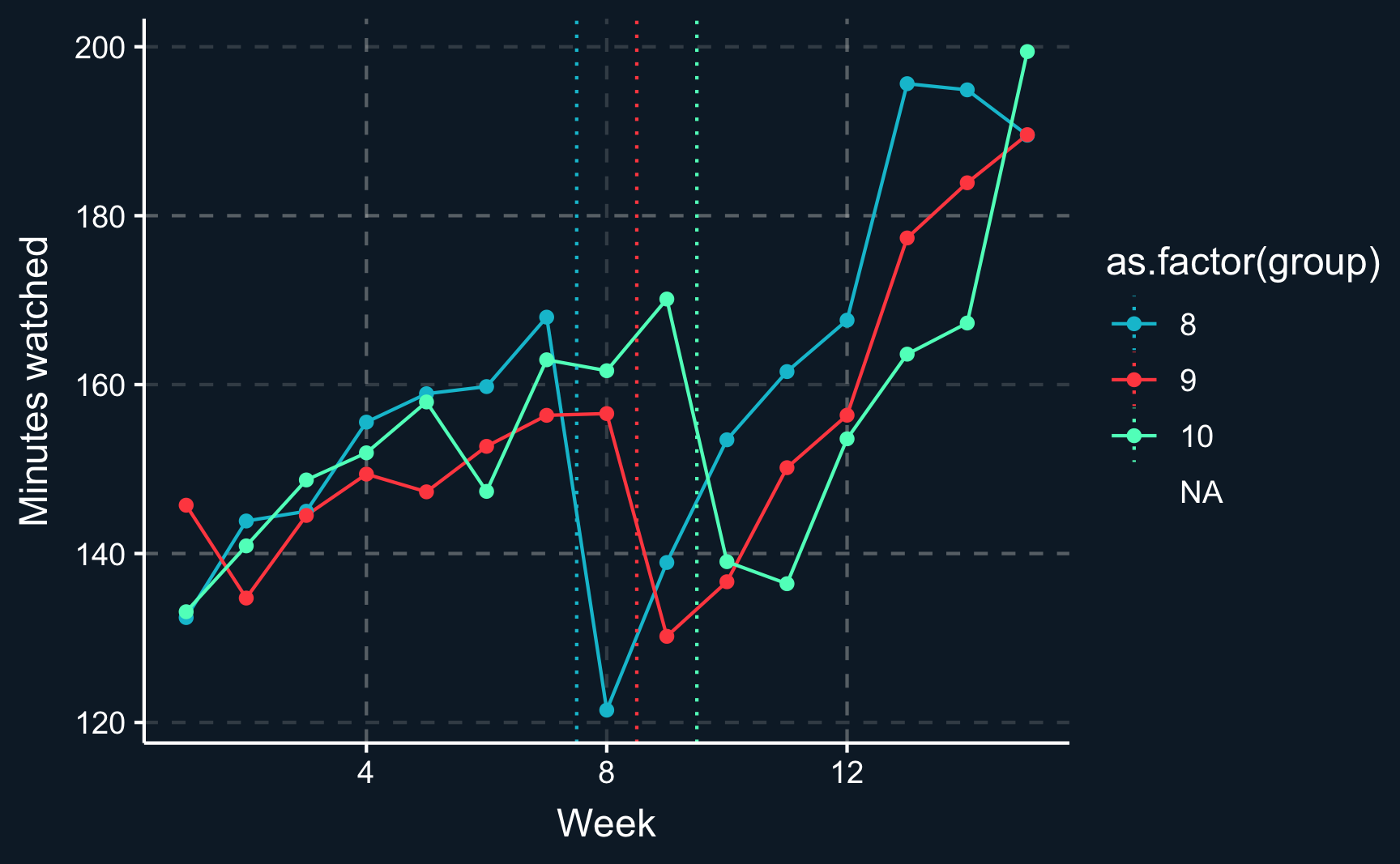
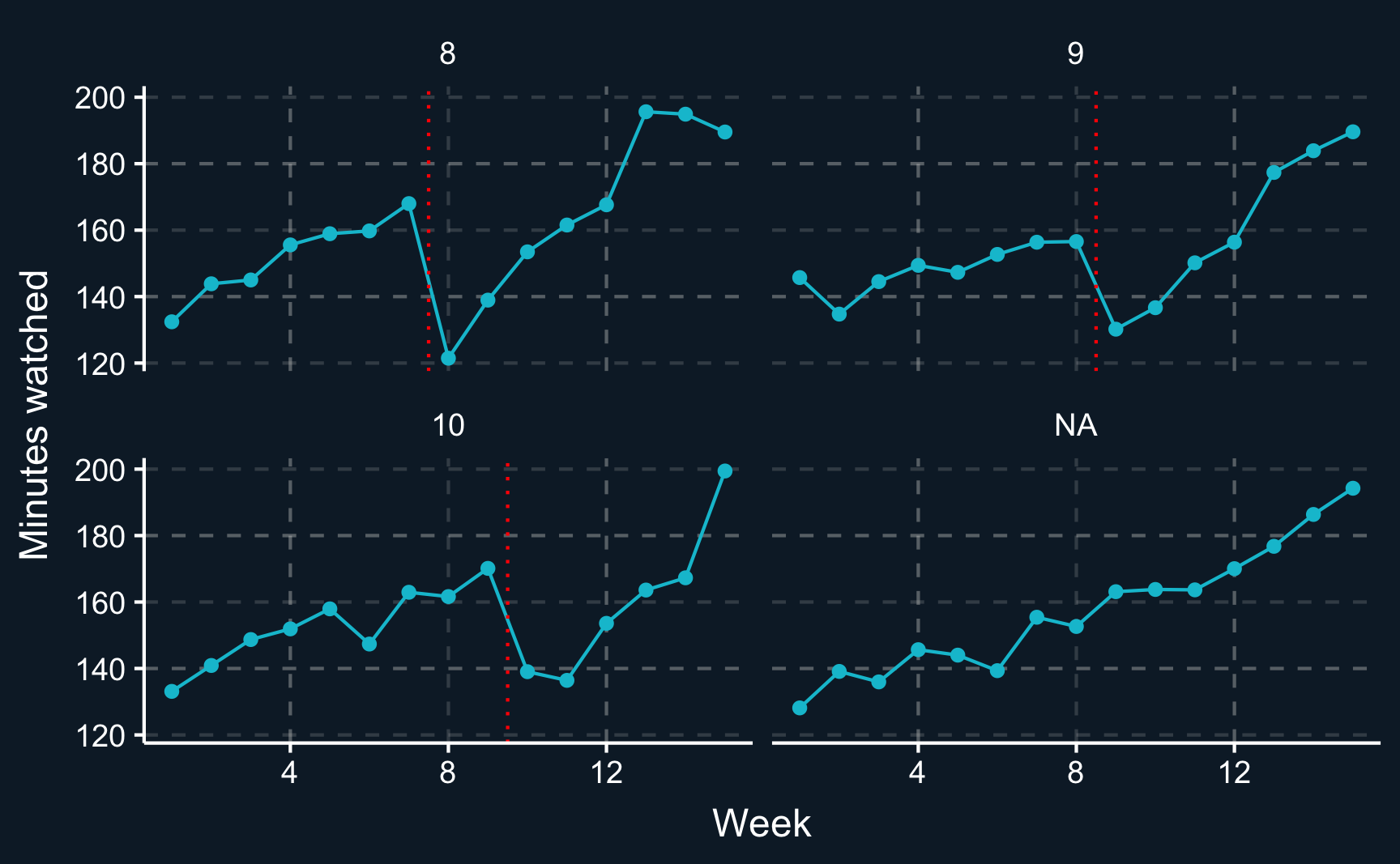
Task 2: Compute and plot the outcome for each cohort (treatment groups + control groups)
before and after the treatment,
and for each period.
# Task 2: compute plot evolution of average outcomes across cohorts.# (a) stream|>group_by(group, d_it)|>summarise(mean_y =mean(minutes_watched))|>ungroup()
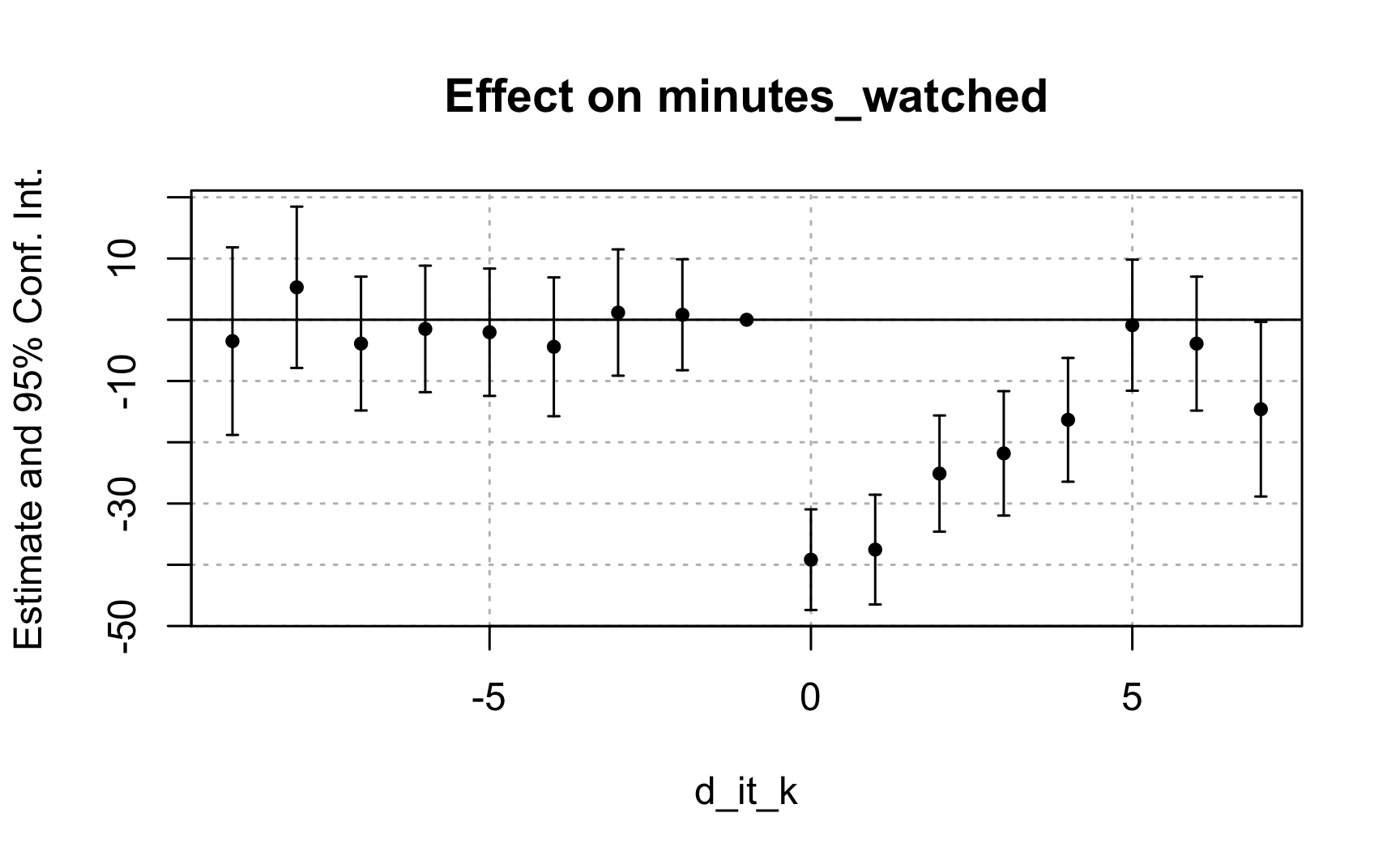
Let’s run an event study to assess the plausibility of our assumption of parallel trends and no anticipation.
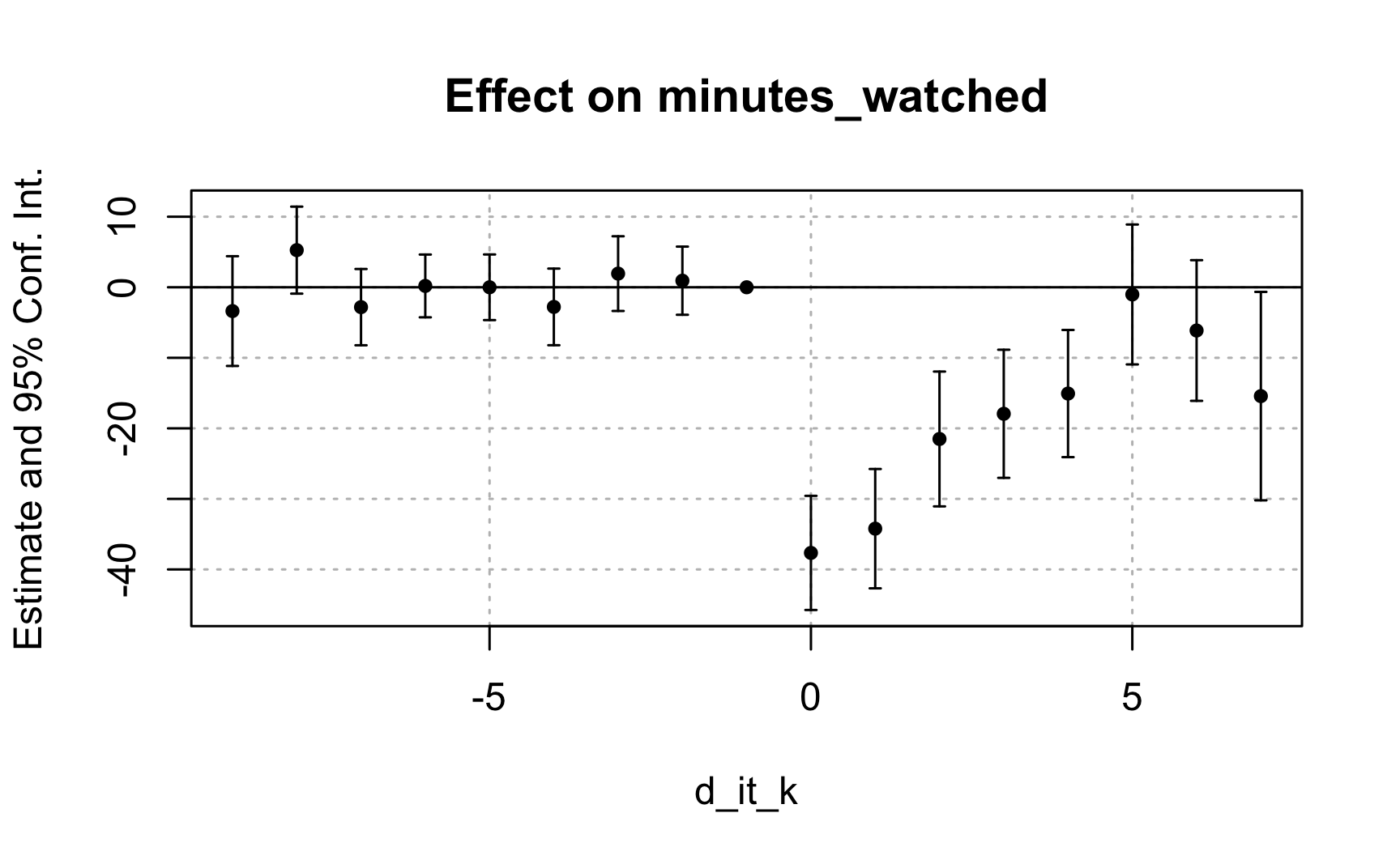
Task 3: Without including covariates, run an event study and assess whether the assumption of parallel trends holds.
# Task 3: Run an event-study without covariates to assess the parallel trends# assumption.evt_stdy_wo<-fixest::feols(minutes_watched~i(d_it_k, ref =c(-1, Inf))|unit+time, data =stream)summary(evt_stdy_wo)
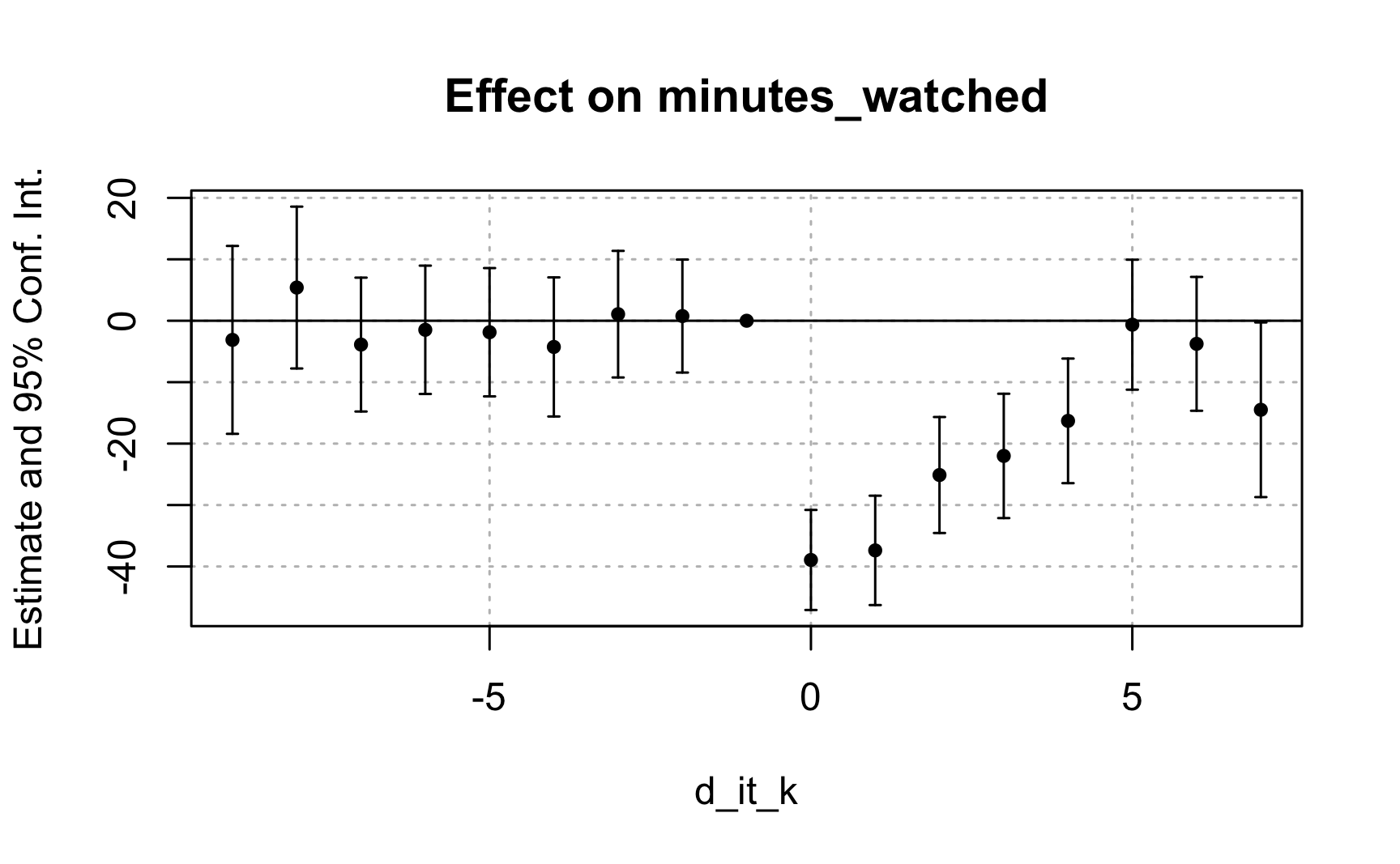
Task 4: Including covariates, run an event study and assess whether the assumption of parallel trends holds.
# Task 4: Run an event-study with covariates to assess the conditional parallel trends# assumption.evt_stdy_w<-fixest::feols(minutes_watched~i(d_it_k, ref =c(-1, Inf))+age+gender+account_tenure+num_drama_watched+num_comedy_watched+num_action_watched|unit+time, data =stream)
The variables 'age', 'gender' and 'account_tenure' have been removed because of collinearity (see $collin.var).
Task 5: Compute the static treatment effect using TWFE (w and w/o).
# Task 6: Compute the static treatment effect using TWFE (w and w/o).twfe_wo<-fixest::feols(minutes_watched~i(d_it, ref =c(0))|unit+time, data =stream)twfe_w<-fixest::feols(minutes_watched~i(d_it, ref =c(0))+age+gender+account_tenure+num_drama_watched+num_comedy_watched+num_action_watched|unit+time, data =stream)
The variables 'age', 'gender' and 'account_tenure' have been removed because of collinearity (see $collin.var).
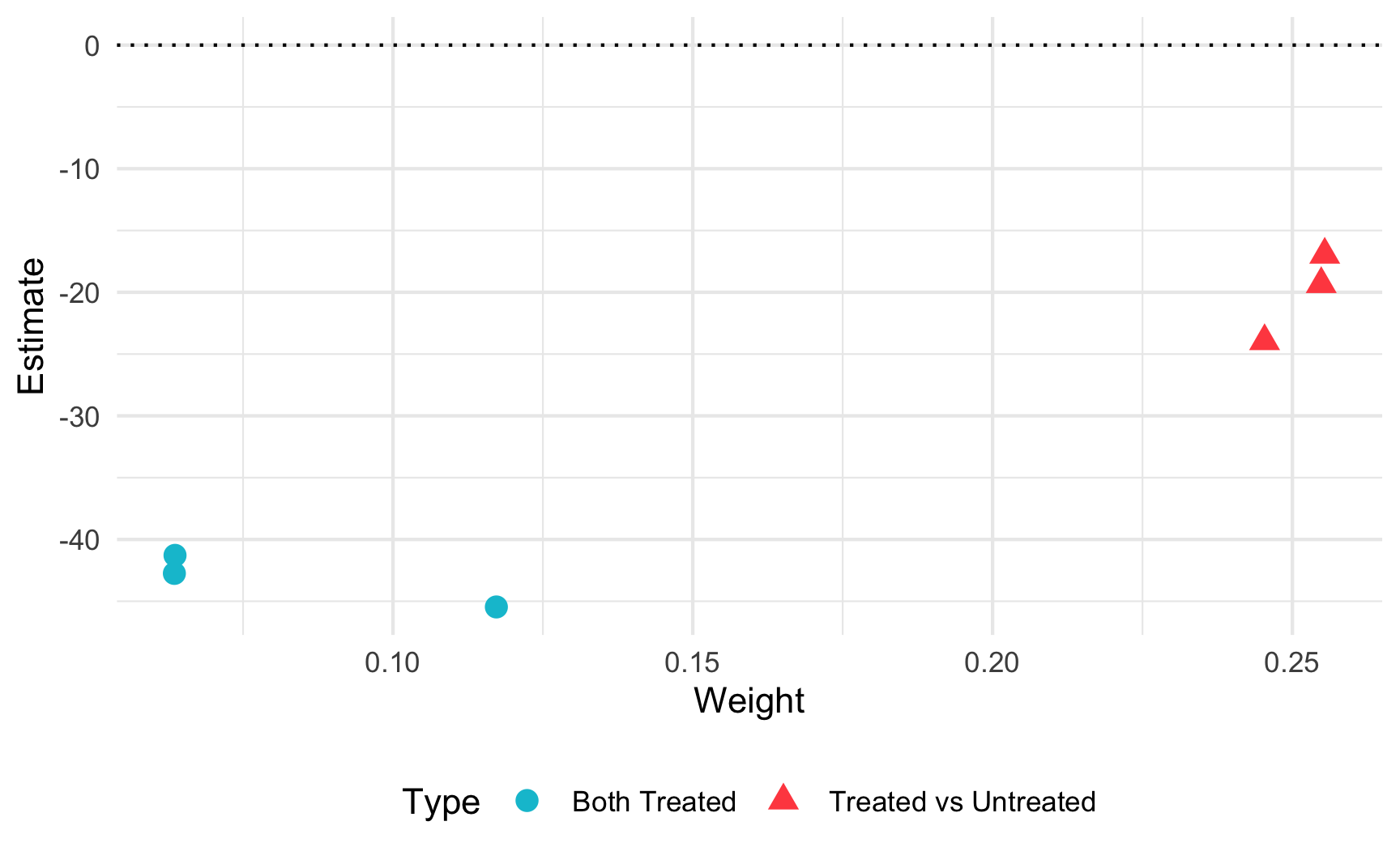
As discussed in the lecture, when treatment adoption is staggered, the two-way fixed effects estimator yields biased results in the presence of treatment effect heterogeneity, i.e., when the treatment effect changes over time. This occurs because some comparisons that should be excluded are still executed by TWFE. Andrew Goodman-Bacon was the first to notice and explain this issue. He decomposed the treatment effect into all possible 2x2 comparisons, showing which comparisons are valid and which are not when we cannot assume treatment effect homogeneity over time. The R package bacondecomp helps visualize these comparisons. Let’s use it to examine our case.
# Bacon-Decompositionlibrary(bacondecomp)# What comparisons are included in TWFE?df_bacon<-bacon(minutes_watched~d_it+age+gender+account_tenure+num_drama_watched+num_comedy_watched+num_action_watched, data =stream, id_var ="unit", time_var ="time")
type weight avg_est
1 Both Treated 0.24 -44
2 Treated vs Untreated 0.76 -20
# Plot comparisonsggplot(df_bacon$two_by_twos)+aes(x =weight, y =estimate, shape =factor(type), color =factor(type))+geom_point(size =3)+geom_hline(yintercept =0, color ="black", linetype ="dotted")+theme_minimal()+labs(x ="Weight", y ="Estimate", shape ="Type", color ="Type")+theme(legend.position ="bottom")
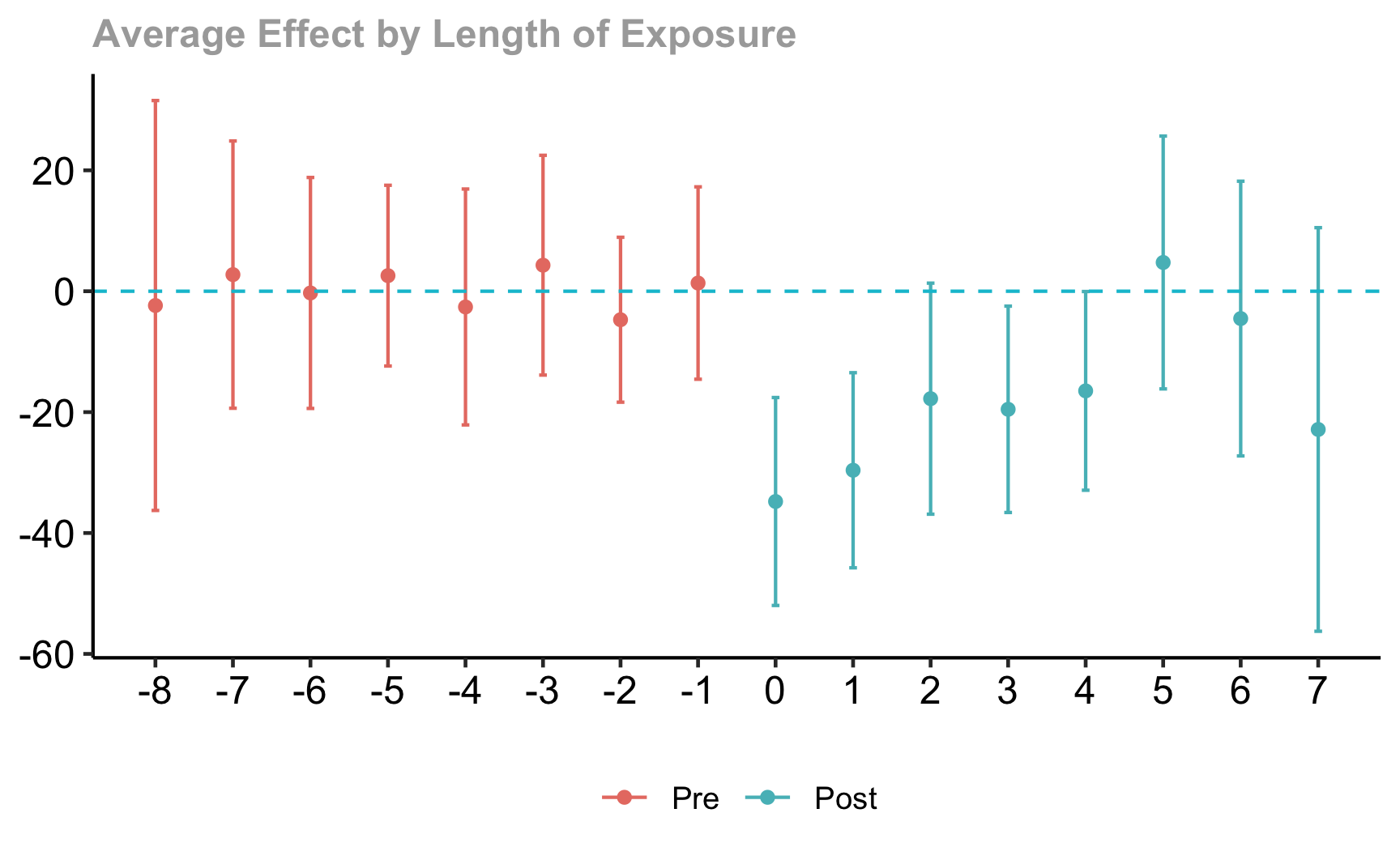
Task 6: Use any method that is robust to treatment effect heterogeneity for staggered treatment adoption. Retrieve a static and a dynamic estimate and plot your result. Using the result from the Bacon-Decomposition, compare the estimate to the TWFE estimate.
Call:
did::aggte(MP = drdid, type = "simple")
Reference: Callaway, Brantly and Pedro H.C. Sant'Anna. "Difference-in-Differences with Multiple Time Periods." Journal of Econometrics, Vol. 225, No. 2, pp. 200-230, 2021. <https://doi.org/10.1016/j.jeconom.2020.12.001>, <https://arxiv.org/abs/1803.09015>
ATT Std. Error [ 95% Conf. Int.]
-18 4.2 -26 -9.5 *
---
Signif. codes: `*' confidence band does not cover 0
Control Group: Never Treated, Anticipation Periods: 0
Estimation Method: Doubly Robust
Running Two-stage Difference-in-Differences
- first stage formula `~ age + gender + account_tenure + num_drama_watched + num_comedy_watched + num_action_watched | unit + time`
- second stage formula `~ i(d_it, ref = 0)`
- The indicator variable that denotes when treatment is on is `d_it`
- Standard errors will be clustered by `unit`
Running Two-stage Difference-in-Differences
- first stage formula `~ age + gender + account_tenure + num_drama_watched + num_comedy_watched + num_action_watched | unit + time`
- second stage formula `~ i(d_it_k, ref = c(-1, Inf))`
- The indicator variable that denotes when treatment is on is `d_it`
- Standard errors will be clustered by `unit`
Accept the Week 10 - Assignment and follow the same steps as last week and as described in the organization chapter.
Please also remember to fill out the course evaluation if you have not done so already.
Explain in your own words in 3-4 sentences, when and why the estimation of treatment effects using TWFE yields biased estimate in the case of staggered adoption and multiple treatment periods.
One week prior to introducing the unskippable ads, you notify your users in an email. Explain, how that could affect your estimation and the assumption it relies on. Independent of your conclusion, show how you can account for anticipation when using the estimator from the did2s package (Gardner, Thakral, Tô, and Yap (2024)).
Using the robust estimator from the did package (Callaway & Sant’Anna (2021)), perform a sensitivity analysis using the HonestDiD package. Additional to the lecture slides, you can find instructions on installation, functionality, and theory on GitHub. Run the sensitivity analysis based on “bounds on relative magnitudes” and explain the result in your own words (3-4 sentences). Please note that you have to set base_period = "universal" in att_gt().