So far, we have primarily discussed cross-sectional data, where each unit is observed only once. However, sometimes you can observe units over multiple time periods, resulting in panel data. This allows us to see how a unit changes before and after a treatment. When randomization isn’t feasible, panel data is the best alternative for identifying causal effects. The most well-known method for estimating this effect is called difference-in-differences (DiD).
Panel Data
In marketing, randomization is often impractical because you cannot always control who receives the treatment. For instance, let’s say you decide to place billboards in a city to advertise your app, aiming to measure the resulting number of downloads attributed to these billboards. You will advertise in some cities but not in others, creating a geo experiment. Additionally, you will track several time-invariant covariates:
\(age_i\): age average in city \(i\)
\(population\_size_i\): integer indicating population size of city \(i\)
\(user\_share_i\): initial share of app users prior to observation period in city \(i\)
\(competitor\_price_i\): average of competitor app price in that given area
Unlike your competitor, your app is free to download, and you plan to generate revenue within the app. Our observed units are cities \(i\) over multiple time periods \(t\). Let’s have a look at the data.
We see that for city \(i=1\), we have eight months with \(post = 0\) and 1 month with \(post = 1\). The outcome changes over time but the covariates are time invariant. Please also note that the treatment indicator indicates whether a unit was “ever” treated.
When counting the number of control and treatment units per period, we’ll see that we have a complete panel without any missing data.
Not always you will have several pre-treatment periods and DiD already works when you only observe one period before and one period after the treatment. So let’s image that scenario and later re-introduce the other pre-treatment periods.
# Last pre-treatment and post-treatment perioddf_2p<-df|>filter(month%in%8:9)# Printprint(df_2p|>count(month, ever_treated, post))
Because we observe both control and treated units before and after the treatment, we can compute the treatment effect \(\tau_{\text{DiD}}\) using the difference-in-differences method. This involves first calculating the difference in outcomes between the treated and control groups after the treatment, then subtracting the difference in outcomes between these groups before the treatment. This double differencing helps isolate the treatment effect.
Regression with treatment and time dummy, as well as interaction of treatment and time.
\[
Y_{i,t} = \alpha + \beta D_i + \gamma t + \tau_{\text{DiD}} (D_i \times t) + \epsilon_{i,t}
\]Task 2: Perform both approaches and report the estimated coefficient.
Code
# (1)mod_1<-lm(downloads~ever_treated:post+as.factor(city)+as.factor(month), data =df_2p)# Coefficientcoef_mod_1<-mod_1$coefficients["ever_treated:post"]sprintf("%.2f", coef_mod_1)
[1] "14.86"
Code
# (2)mod_2<-lm(downloads~ever_treated*post, data =df_2p)summary(mod_2)
Call:
lm(formula = downloads ~ ever_treated * post, data = df_2p)
Residuals:
Min 1Q Median 3Q Max
-489.1 -54.8 -3.8 55.5 564.1
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 516.7 11.3 45.93 <2e-16 ***
ever_treated 48.8 15.2 3.20 0.0015 **
post 29.0 15.9 1.82 0.0691 .
ever_treated:post 14.9 21.6 0.69 0.4908
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 107 on 396 degrees of freedom
Multiple R-squared: 0.0911, Adjusted R-squared: 0.0842
F-statistic: 13.2 on 3 and 396 DF, p-value: 3.01e-08
For two-way fixed effects estimation, we can generally also use the lm() command which we have used for so many applications already. However, it is recommended to use the fixest package due to its increased speed and focus on fixed effects. As it is the workhorse of many other packages, let’s get it installed.
The formula notation is slightly different as we separate the fixed effects using the | operator. This approach allows the algorithm to converge faster, and the fixed effects will not appear in the regression summary. Since fixed effects are typically not of primary interest and we often have a large number of them, this simplification is quite convenient.
Code
# Faster way for (1)library(fixest)summary(feols(downloads~ever_treated:post|city+month, data =df_2p))
Here, where we only have two time period, we need to rely on one assumption to hold: the parallel trends assumption. Opposed to methods where we just know one outcome - the “after” outcome, regardless of whether a unit received or did not receive treatment - we do not have to assume that the potential outcomes are equal \((Y_1(0)-Y_0(0)) \perp\!\!\!\perp T\). That is a big difference, because do not have to assume that observation units are similar in all their characteristics. Instead DiD hinges on a different assumption, the parallel trends assumption. It says that, in absence of treatment for both groups, they would be expected to evolve similarly over time. In other words, we do not expect the potential outcome to be similar, but only the change of outcomes from before to after. It implies that there is no factor that has only an impact on just one of the groups.
While the parallel trends assumption is generally untestable, in the case with only two periods, we are particularly in the dark.
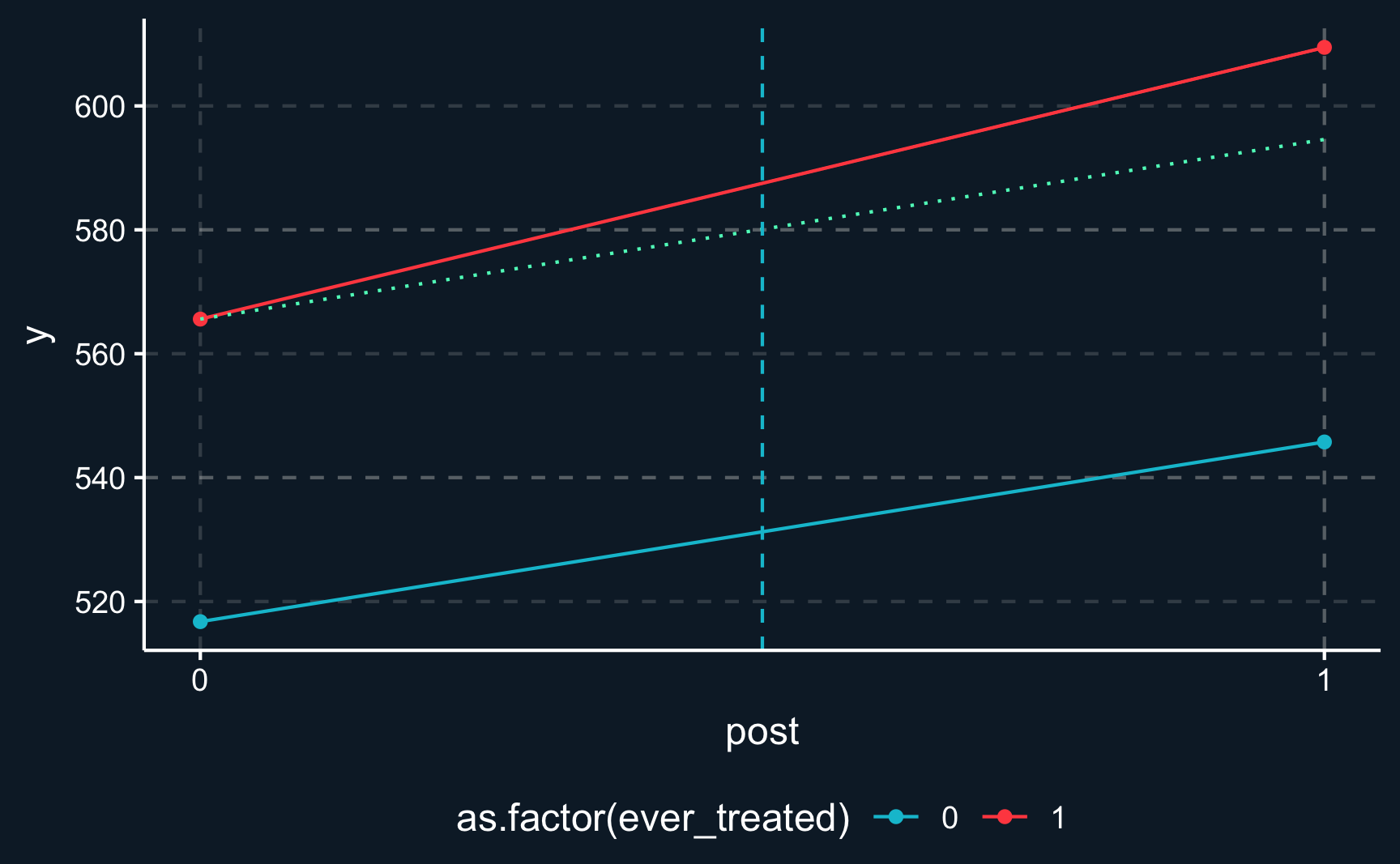
Graphically, what we assume is that the treated line would have evolved similarly to the control line - as depicted by the dotted line. What can we do to increase the plausibility of this assumption?
Code
y10<-did_p2[did_p2$ever_treated==1&did_p2$post==0, ]$yy01<-did_p2[did_p2$ever_treated==0&did_p2$post==1, ]$yy00<-did_p2[did_p2$ever_treated==0&did_p2$post==0, ]$ydata_cf<-tibble( x =c(0, 1), y =c(y10, y10+(y01-y00)))ggplot(did_p2, aes(x =post, y =y, group =ever_treated, color =as.factor(ever_treated)))+geom_point()+geom_line()+geom_line(data =data_cf, aes(x=x, y=y, group =NA), color="#5AFFC5", linetype ="dotted")+geom_vline(xintercept =.5, linetype ="dashed")+scale_x_continuous(breaks=c(0,1))+theme(legend.position ="bottom")
Warning: The `scale_name` argument of `discrete_scale()` is deprecated as of ggplot2 3.5.0.
Testing for parallel trends
There is some remedy when we are able to observe multiple periods prior to the treatment. By comparing trends before treatment between the treatment and control groups, researchers aim to demonstrate that there was no significant difference prior to the treatment. The logic is that if there was no difference before treatment, any difference observed after the treatment is likely due to the treatment itself.
However, even that cannot provide full certainty about the parallel trends assumption. There may still be unobserved factors that could affect the treatment. Nevertheless, event studies are a useful tool for arguing that the treatment and control groups are comparable.
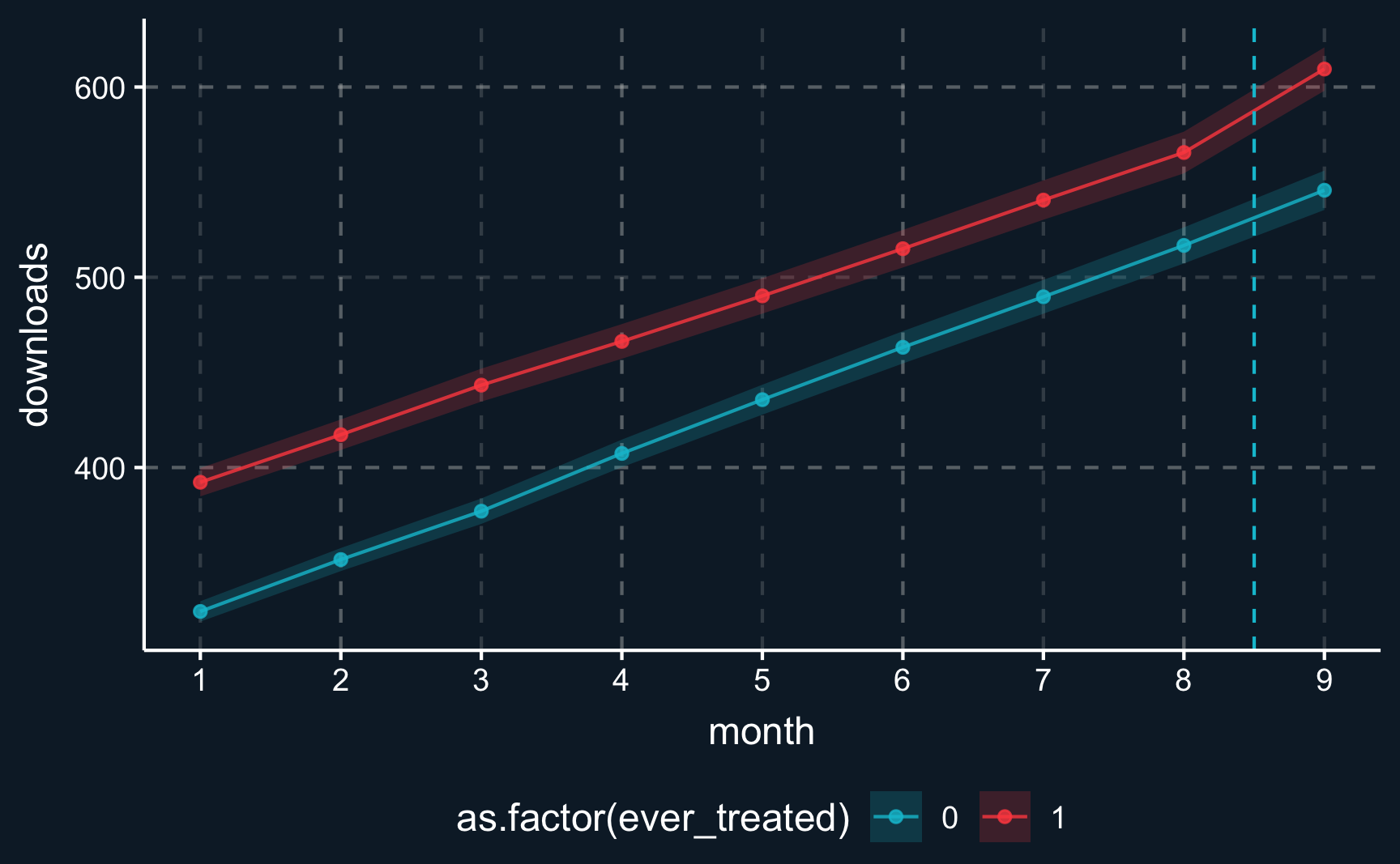
Let’s now switch back to the dataset with multiple pre-treatment periods and begin by plotting the observed outcomes over time. This will help us determine if there are converging or diverging trends between the treatment and control groups. By visualizing these trends, we can already assess whether the parallel trends assumption holds before the treatment.
# Outcomes across time by groupdf|>ggplot(aes( x =month, y =downloads, fill =as.factor(ever_treated), color =as.factor(ever_treated)))+stat_summary(fun.data =mean_se, geom ="point", alpha =.8)+stat_summary(fun.data =mean_se, geom ="line", alpha =.8)+stat_summary(fun.data =mean_se, geom ="ribbon", alpha =.2, color =NA)+geom_vline(xintercept =8.5, linetype ="dashed")+scale_x_continuous(breaks=1:9)+theme(legend.position ="bottom")
At the first glance, prior to the treatment, the outcomes seem to evolve in parallel. However, a better way is to actually perform statistical tests and check the hypothesis that the evolution of both groups is parallel. For each difference between two pre-treatment periods, the should be no difference in the evolution of the outcomes across the treatment groups.
Task 3a: Subset the data so you can perform test for pre-trends between the pre-treatment months 7 and 8 using the TWFE approach from above.
Code
df_placebo<-df|>filter(month%in%c(7, 8))|>mutate(post =if_else(month==8, 1, 0))summary(feols(downloads~ever_treated:post|city+month, data =df_placebo))
With this approach, you would have to iterate through quite a lot of combinations. Another approach would be to add “fake” post columns to the data frame and interact them with the treatment indicator.
Task 4: Subset the data so you can perform test for pre-trends between ALL two arbitrary pre-treatment periods using the TWFE approach from above. You’ll need to create new columns with e.g. post_t = if_else(month == t, 1, 0), where t is a treatment period and introduce new interactions into the formula.
An even more programmatic way to test for pre-trends is to run an event study to perform the tests all in one command. We only have to slightly change the input. Instead of the single treatment indicator ever_treated:post, which is only active for the treated group after treatment, we include several interactions which cover all periods for the treated group.
We can do so with the help of i() from the fixest package and a newly created variable that measures the time distance to the treatment period.
Code
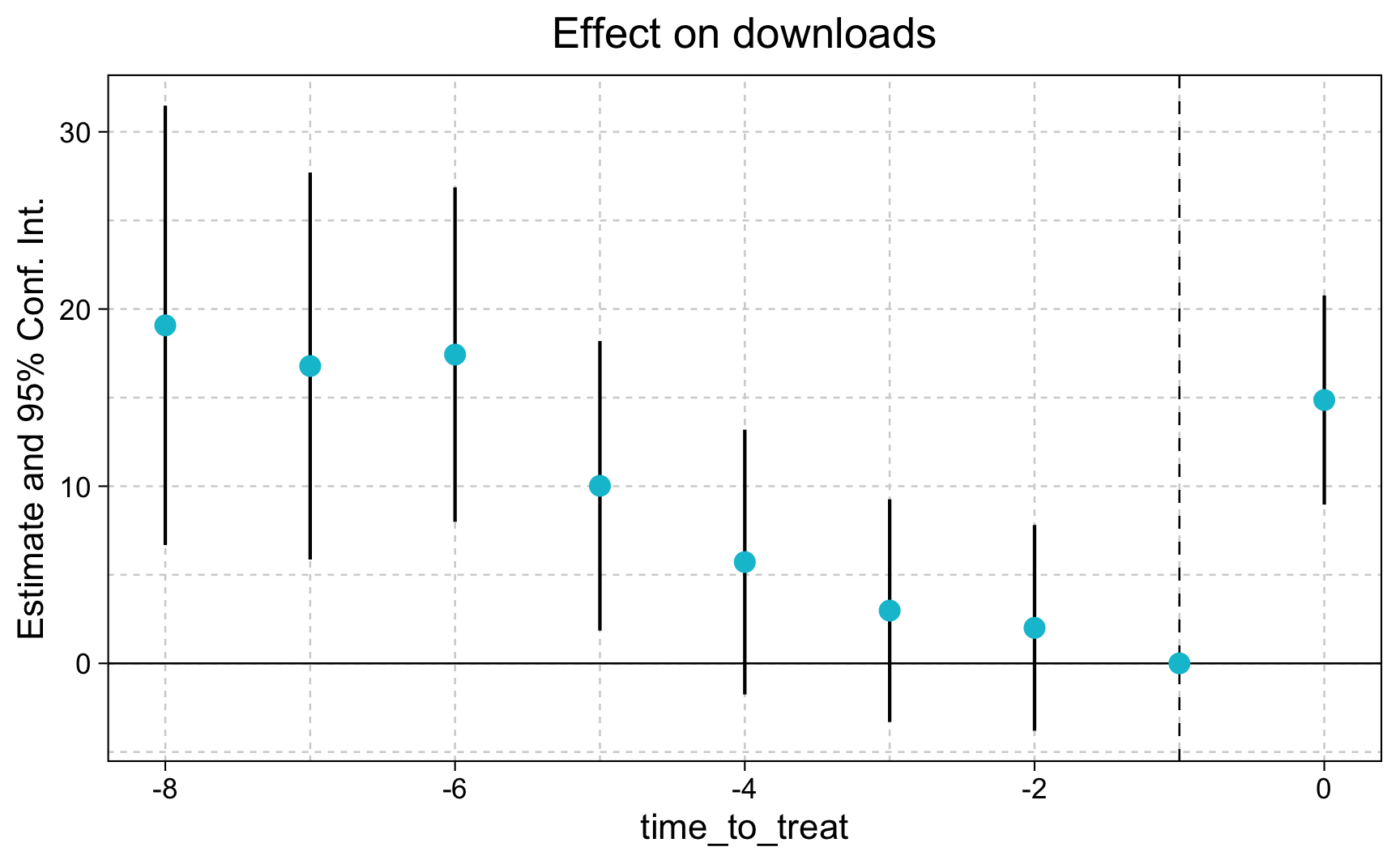
# Create time distance columntreat_month<-9df<-df|>mutate(time_to_treat =if_else(ever_treated==1, month-treat_month, 0))evt_stdy<-feols(downloads~i(time_to_treat, ever_treated, ref =-1)|city+month, data =df)summary(evt_stdy)
Using iplot() we can visualize the multiple treatment effects. Any treatment effect prior to the treatment is a big cause of concern with regards to the parallel trends assumption.
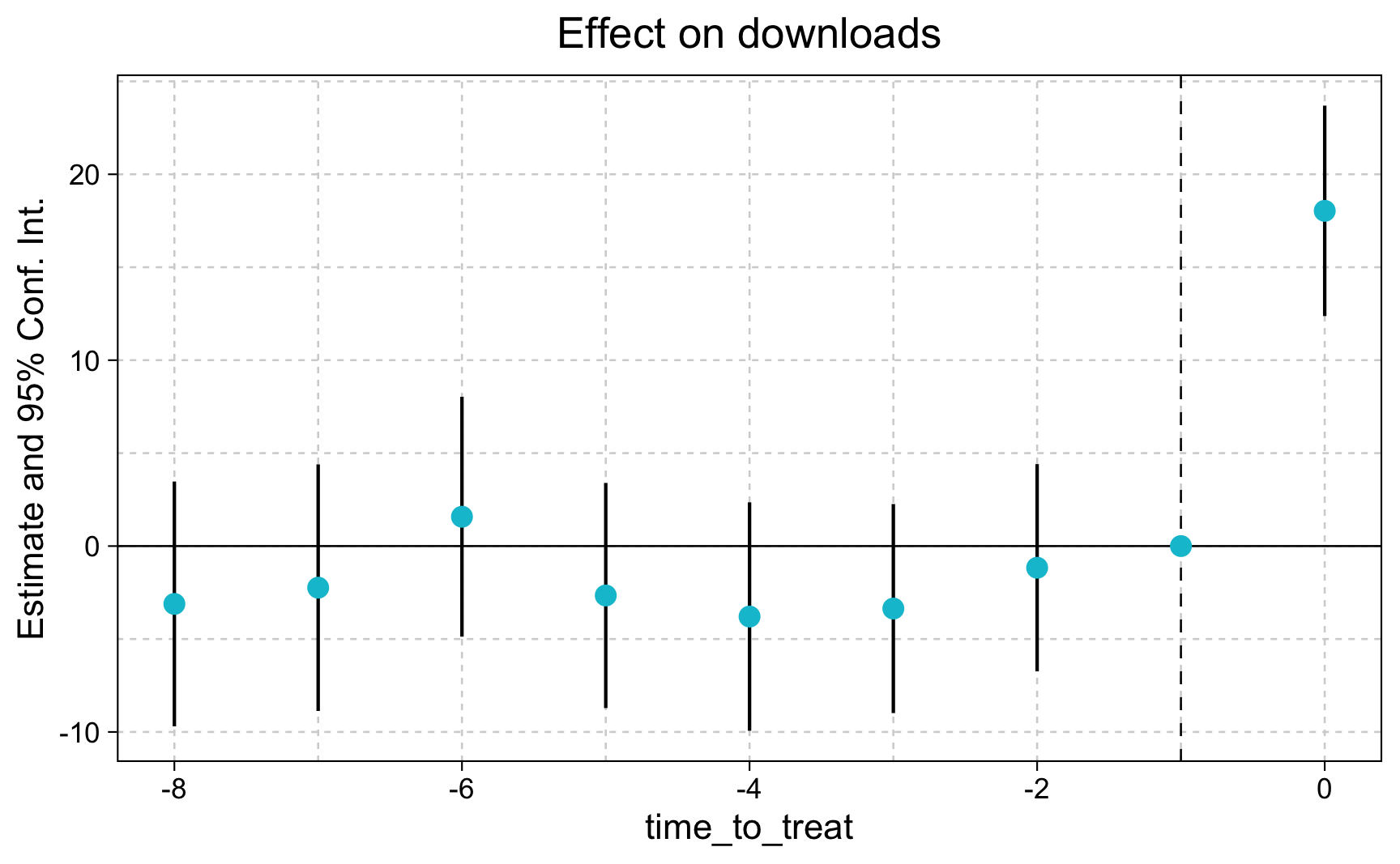
Now, we have seen that we cannot assume parallel trends - there are significant differences in the evolution of outcomes. But what can we do to increase the plausibility of assuming parallel trends? One approach that is widely been used in practice is the inclusion of covariates. But as you have learned in the lecture, you have to be extremely careful.
What you obtain then is the conditional parallel trends assumption, which is the assumption of parallel trends conditional on covariates.
# Time-invariant, but time-varying effects.evt_stdy_cond_2<-feols(downloads~i(time_to_treat, ever_treated, ref =-1)+age:month+user_share:month+population_size:month+competitor_price:month|city+month, data =df)evt_stdy_cond_2
During the last weeks we have already learned the advantages of doubly robust estimation and in fact, there is a doubly robust DiD estimator proposed by Sant’Anna and Zhao, 2020 and implemented in the DRDID package.
Call:
drdid(yname = "downloads", tname = "post", idname = "city", dname = "ever_treated",
xformla = ~age + user_share + population_size + competitor_price,
data = df_2p)
------------------------------------------------------------------
Further improved locally efficient DR DID estimator for the ATT:
ATT Std. Error t value Pr(>|t|) [95% Conf. Interval]
18.6812 3.2087 5.822 0 12.3922 24.9703
------------------------------------------------------------------
Estimator based on panel data.
Outcome regression est. method: weighted least squares.
Propensity score est. method: inverse prob. tilting.
Analytical standard error.
------------------------------------------------------------------
See Sant'Anna and Zhao (2020) for details.
Task 7: Following the same syntax, use the outcome regression adjustment with ordid() and the inverse probability weighting approach ipwdid() to estimate the treatment effect.
Call:
ordid(yname = "downloads", tname = "post", idname = "city", dname = "ever_treated",
xformla = ~age + user_share + population_size + competitor_price,
data = df_2p)
------------------------------------------------------------------
Outcome-Regression DID estimator for the ATT:
ATT Std. Error t value Pr(>|t|) [95% Conf. Interval]
19.2478 3.2017 6.0117 0 12.9724 25.5232
------------------------------------------------------------------
Estimator based on panel data.
Outcome regression est. method: OLS.
Analytical standard error.
------------------------------------------------------------------
See Sant'Anna and Zhao (2020) for details.
Call:
ipwdid(yname = "downloads", tname = "post", idname = "city",
dname = "ever_treated", xformla = ~age + user_share + population_size +
competitor_price, data = df_2p)
------------------------------------------------------------------
IPW DID estimator for the ATT:
ATT Std. Error t value Pr(>|t|) [95% Conf. Interval]
18.7472 3.3073 5.6684 0 12.2648 25.2296
------------------------------------------------------------------
Estimator based on panel data.
Hajek-type IPW estimator (weights sum up to 1).
Propensity score est. method: maximum likelihood.
Analytical standard error.
------------------------------------------------------------------
See Sant'Anna and Zhao (2020) for details.
Assignment
Accept the Week 9 - Assignment and follow the same steps as last week and as described in the organization chapter.
Please also remember to fill out the course evaluation if you have not done so already.
Explain under what circumstances a time-invariant covariate can be a confounder.
Explain under what circumstances a time-varying covariate can be a confounder.
Let’s consider the variable competitor_price was time-variant and for each period, we would observe the price in the same period set by the competitor. Do you see any risk in using this variable?
Apply the doubly robust estimator with ML from the lecture to the data from the tutorial. Use the models "regr.xgboost" and "classif.xgboost". Additionally, implement cross-fitting (K=5). Report and compare the result to the other estimates.
Check what happens when you simulate a misspecification of the outcome model by replacing delta_mu with sample(delta_mu, replace = FALSE) or a misspecification of the exposure model by replacing ehat with sample(ehat, replace = FALSE). Report and discuss your result.