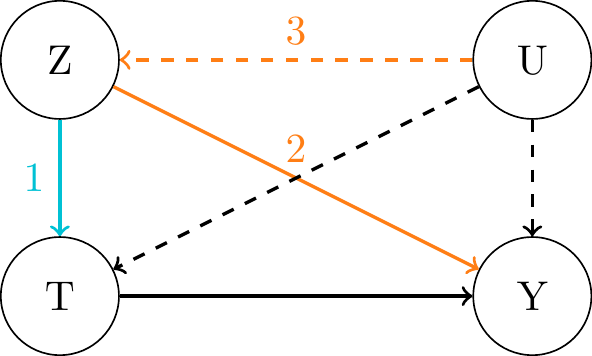
Relevance: \(Z\) is significantly correlated with \(T\), i.e. \(Cov(Z, T) \neq 0\). Path 1 must exist.
Exclusion Restriction: \(Z\) affects \(Y\) only through \(T\). A direct path 2 must not exist.
Unconfoundedness (Exogeneity, Validity): \(Z\) is independent of \(U\), i.e. \(Cov(Z, \epsilon_Y) = 0\). Conditioning on \(\mathbf{X}\) required in some contexts (will cover this later). Path 3 must not exist.
For our practical example, imagine the following situation: you have developed an app and you are already having an active user base. Of course, some users are more active than other users. Also, users might use the app for different purposes. In general, user behavior likely depends on a lot of unobserved characteristics.
Obviously, your goal is to keep users as long as possible on the app to maximize your ad revenues. To do that, you want to introduce a new feature and see how it affects time spent on the app. Simply comparing users who use the newly introduced feature to users who don’t would result in a biased estimate due to the unobserved confounders regarding their activity and willingness to use a new feature.
Therefore, you perform a so called randomized encouragement trial, where for a random selection of users, a popup appears when opening the app and encourages these users to test new feature. The users who are not randomly selected don’t get a popup message but could also use the new feature.
After a while you collect data on users’ activity and also if they were encouraged and if they used the new feature. Download the data and load it.
Causal Effect: The impact of a new feature on the time spent in the app.
Treatment: Usage of the new feature.
Outcome: Time spent in the app.
Instrument: Randomized encouragement (e.g., a popup message encouraging users to try the new feature).
This setup avoids running an A/B test on the feature itself by using an encouragement design, which is often more acceptable from a business perspective, particularly when there is a desire to roll out a feature to all users.
Question: Does the randomized encouragement (popup message) affect the likelihood of using the new feature?
Evaluation: It is plausible that the encouragement message will increase the probability that users try the new feature, satisfying the relevance condition.
Exclusion Restriction
Question: Does the randomized encouragement affect the time spent in the app only through its effect on the usage of the new feature?
Evaluation: Assuming the only reason the encouragement affects the time spent in the app is by increasing the use of the new feature, this condition holds. The popup message should not directly affect time spent in the app other than by leading users to use the new feature.
Unconfoundedness
Question: Is the random assignment of encouragement independent of potential outcomes and treatments?
Evaluation: Since the encouragement is randomized, it should be independent of other factors that could influence both the usage of the new feature and the time spent in the app, satisfying this condition.
Parametric identification of ATE
As in our practical example, we will derive the ATE for the binary case, i.e. a binary instrument and a binary treatment variable. However, the continuous case is very similar. For the parametric identification, we assume linearity. In other words, we assume a homogeneous treatment effect and exclude effect heterogeneity with regard to unobserved variables.
\[
Y_i = \beta_0 + \tau T_i + \beta_U U_i + \epsilon_i
\] Please note, that there is no \(Z\) in this formula due to the exclusion restriction.
Let’s go through the identification procedure step by step. You will see and use the other assumptions there, as well.
We start with the associational difference for \(Y\) under different values for \(Z\). It’s not the treatment effect \(\tau\), but because we can observe this expression, we take it as a starting point.
A more practical way of estimating the treatment effect is the two-stage least squares estimator (2SLS) which returns an estimate equivalent to the one just computed. 2SLS splits the estimation procedure in two stages:
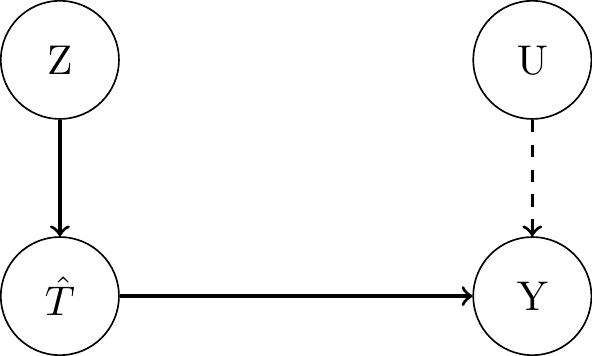
1st stage: regress \(T\) on \(Z\) to obtain \(\hat{T}\), where \(\hat{T}\) are the fitted values.
2nd stage: regress \(Y\) on \(\hat{T}\) to obtain the coefficient \(\hat{\tau}\), which is the treatment effect.
In the graphs below, you can see how the 2SLS estimator works. First, \(U\) is an unobserved confounder of \(T\) on \(Y\). When replacing \(T\) with \(\hat{T}\), there is no arrow from \(U\) on the adjusted treatment, because there is no dependence.
Task 3: Compute the treatment effect using the 2SLS estimator as described. (1) First, do it by running the two regressions. (2) Then, use the R package AER and the function ivreg(). The syntax for the formula is: Y ~ T | Z. (Note: for method (1) your standard errors will be wrong. You can ignore that for now.)
# (a) with wrong standard errors# First stagestage_1<-lm(used_ftr~popup, data =df)summary(stage_1)
Call:
lm(formula = used_ftr ~ popup, data = df)
Residuals:
Min 1Q Median 3Q Max
-0.659 -0.309 -0.309 0.341 0.691
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.30941 0.00667 46.4 <2e-16 ***
popup 0.35002 0.00937 37.4 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.47 on 9998 degrees of freedom
Multiple R-squared: 0.123, Adjusted R-squared: 0.122
F-statistic: 1.4e+03 on 1 and 9998 DF, p-value: <2e-16
# Second stagedf$used_ftr_hat<-stage_1$fitted.valuesstage_2<-lm(time_spent~used_ftr_hat, data =df)summary(stage_2)
Call:
lm(formula = time_spent ~ used_ftr_hat, data = df)
Residuals:
Min 1Q Median 3Q Max
-41.66 -7.36 0.28 7.87 31.94
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 62.273 0.322 193.2 <2e-16 ***
used_ftr_hat 9.309 0.623 14.9 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 11 on 9998 degrees of freedom
Multiple R-squared: 0.0218, Adjusted R-squared: 0.0217
F-statistic: 223 on 1 and 9998 DF, p-value: <2e-16
# (b) with correct standard errors# Load packagelibrary(AER)
Warning: Paket 'AER' wurde unter R Version 4.3.2 erstellt
Warning: Paket 'survival' wurde unter R Version 4.3.3 erstellt
# Two-stage least squarestsls<-ivreg(time_spent~used_ftr|popup, data =df)summary(tsls, vcov =vcovHC)# with robust standard errors
Call:
ivreg(formula = time_spent ~ used_ftr | popup, data = df)
Residuals:
Min 1Q Median 3Q Max
-35.52 -6.03 0.62 6.63 27.28
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 62.273 0.270 230.5 <2e-16 ***
used_ftr 9.309 0.524 17.8 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.2 on 9998 degrees of freedom
Multiple R-Squared: 0.308, Adjusted R-squared: 0.308
Wald test: 316 on 1 and 9998 DF, p-value: <2e-16
Nonparametric identification of Local ATE
The linearity assumption is a very strong parametric assumption, as it e.g. requires homogeneous treatment effects. Therefore, we would like to nonparametrically identify the treatment effect, and in fact, we can. However, we are not able to identify the average treatment effect ATE, but instead a local version of the average treatment effect, known as LATE. While we can drop the linearity assumption, now the assumption of monotonicity is needed. But first, we have to introduce a bit of new notation to express the relationship between instrument and treatment. The notation is similar to the potential outcome notation.
Principal stratification
We segment population into four segments. E.g. \(T_i(Z = 1) = 1\) represents unit’s \(i\) decision to “get the treatment” when being encouraged. Based on all possible combinations, four different exist:
Compliers always take the treatment that they’re encouraged to take: \(T_i(1) = 1\) and \(T_i(0) = 0\).
Always-Takers always take the treatment, regardless of encouragement: \(T_i(1) = 1\) and \(T_i(0) = 1\).
Never-Takers never take the treatment, regardless of encouragement: \(T_i(1) = 0\) and \(T_i(0) = 0\).
Defiers always take the opposite treatment that they’re encouraged to take: \(T_i(1) = 0\) and \(T_i(0) = 1\).
Applied to our example, usere who receive the encouragement (popup message) and use it are compliers.
Task 4: We are not able to observe whether a unit is a complier, always-taker, never-taker or defier. For each observed combination of \(Z\) and \(T\), there are always two options. For the following combinations, answer what segments could be possible.
In case of unobserved confounding, we will nonparametrically identify the local average treatment effect (LATE), also known as the complier average causal affect (CACE). It is the average tratment effect among compliers.
Instead of linearity, we assume monotonicity: a unit encouraged to take the treatment (\(Z=1\)), is either more or equally likely to take it then without encouragement (\(Z=0\)).
\[
T_i(Z_i=1) \geq T_i(Z_i=0) \,\, \forall i
\]
The monotonicity assumption implies that there are no defiers because they actually always act differently than the compliers.
In our example, monotonicity means that the popup uniformly increase the likelihood of using the new feature, without making any users less likely to use it. And while the assumption is not testable, we could argue that the popup message is unlikely to decrease the likelihood that users try the new feature. Therefore, this condition is likely satisfied.
For the estimation of the LATE, if \(Z_i\) and \(T_i\) are binary instrument and treatment variable, respectively, and monotonicity holds, it follows
The numerator term is also called Intention-to-Treat (ITT) Effect, while the denominator is 1st-stage effect or Complier Share.
Task 6: Compute ITT and complier share for our example. How would the LATE vary with a lower or higher complier share?
Identification examples
Task 7: Finding a good instrument is often times quite difficult due to the requirements discussed above. Read the following identification strategies and evalute their validity.
Case 1: Effect of R&D Expenditure on Innovation Output
Variable
Description
Treatment
R&D expenditure
Outcome
Number of patents filed
Instrument
Firm size
Evaluation
Firm size affects R&D expenditure (relevance) but also likely directly affects innovation output due to economies of scale and other factors, violating the exclusion restriction. [invalid]
Case 2: Effect of Training Programs on Employee Productivity
Variable
Description
Treatment
Participation in a training program
Outcome
Employee productivity measured by output per hour
Instrument
Distance from the employee’s home to the training center
Evaluation
Distance from home to the training center is likely to influence participation in the training program (relevance) but should not directly affect productivity except through participation in the training program (exclusion restriction). [valid]
Case 3: Effect of Marketing Spend on Sales
Variable
Description
Treatment
Marketing expenditure by a firm
Outcome
Sales revenue
Instrument
Introduction of a new marketing budget rule that allocates more funds to marketing based on predefined criteria
Evaluation
The new budget rule affects marketing expenditure (relevance) and is assumed to affect sales only through changes in marketing expenditure (exclusion restriction). Independence holds if the rule is exogenous to other factors affecting sales. [valid]
Case 4: Effect of Employee Benefits on Job Satisfaction
Variable
Description
Treatment
Generosity of employee benefits
Outcome
Job satisfaction score
Instrument
Firm’s overall profitability
Evaluation
Firm profitability may influence the ability to offer generous benefits (relevance), but it also directly affects job satisfaction through other channels like job security and working conditions, violating the exclusion restriction. [invalid]
Assignment
Accept the Week 7 - Assignment and follow the same steps as last week and as described in the organization chapter.
Take the example from the tutorial.
Regress \(Y\) on \(T\).
Regress \(Y\) on \(Z\).
Compare the estimates to the one obtained by instrumental variable regression and argue why the size differs. Why are the two regressions not valid estimates of the treatment effect?
Compute the different bounds presented in the lecture and for each bound, explain in one sentence, in your own words, what is assumed.
Using the data task_3.rds, perform a sensitivity analysis using the package sensemakr as presented in the lecture. The outcome and treatment is the same as in the tutorial, but you have one additional covariate, age. With the results from the sensitivity analysis, answer the following questions.
How sensitive is your estimate to a potential unobserved confounder which is 1x, 2x, or 3x as strong as the variable age?
Interpret the robustness value and explain, in your own words, what it expresses.