Please make sure to read and follow the instructions in Organization before reading this section.
Slides & Recap
Practical example
Christmas example
Consider this scenario: you’re the owner of an online marketplace company that small and medium-sized businesses use to sell advertise and sell their products. The businesses act autonomously regarding prices, advertising etc. Because your revenue depends on the prosperity of these businesses, you want to support them by offering guidance when to implement sales campaigns featuring temporary price drops. From a business perspective, a price drop is beneficial when the increase in number of sold units compensates for the lower price. Therefore,it is important to know the number of additional units sold after a price reduction. For simplicity, we only focus on one particular category, socks, and we examine the weeks leading up to and including Christmas week.
Question: It helps to make oneself as clear as possible what the research question is. So, try to formulate a question that entails very clearly what effect we are interested in.
Answer
What is the impact of a price reduction on the number of units sold?
Now, let’s take a look at some data that you collected which could help you to answer your research question.
Note
library() loads external packages/libraries containing functions that are not built in base R. Here, we load the library tidyverse, which is, in fact, a collection of many useful libraries specifically developed for data science tasks.
If you only need one particular function from a library, you can pick it by the following syntax: library::function().
All libraries/packages you want to use need to be installed first by running install.packages("library_to_install").
# Load packages from the tidyverse# install.packages("tidyverse")library(tidyverse)
Warning: Paket 'ggplot2' wurde unter R Version 4.3.2 erstellt
Warning: Paket 'tidyr' wurde unter R Version 4.3.2 erstellt
# Change the path if neededsales<-read_csv("xmas_sales.csv")# Currently coded as 0/1, we convert to FALSE/TRUEsales$is_on_sale<-as.logical(sales$is_on_sale)
The data consists of the following columns:
store: unique identifier of store
weeks_to_xmas: weekly data for each store leading up to Christmas
avg_week_sales: historical average of sales indicating business size
is_on_sale: sale/price reduction indicator
weekly_amount_sold: average weekly sales during that week
Note
There are many other ways to get a first look at your data instead of simply entering the variable name or use print(). Often times you will see head(data, n) to see the first \(n\) lines. Just the same you can use tail(data, n) to see the \(n\) last lines. If it is mainly numeric data, summary() provides a good overview. If you have many columns, glimpse() from the dplyr package contained in the tidyverse helps you.
# Simply enter the table name to show its contentprint(sales)
Let’ connect the data from the table with the formula notation you have learned in the lecture. First of all, it is important to state that our units of analysis \(i\) are stores.
\(D_i\) denotes the treatment for unit \(i\) and for our example it can take either one of the two values:
\[
D_i=\begin{cases}1 \ \text{if unit i received treatment}\\0 \ \text{otherwise}\\\end{cases}
\]
Don’t be confused by the term treatment, it is not a medical treatment (but can be) and other terms used are intervention or manipulation. Here, the treatment \(D_i\) is whether a store dropped its prices in a particular week.
Tip
Sometimes, you will encounter \(T_i\) instead of \(D_i\). But because in R, T is used to abbreviate the boolean value TRUE and in many other applications, \(T\) is reserved for time, we will use \(D\) instead.
Question: What is the data equivalent for the outcome \(Y_i\)?
Answer
It is weekly_amount_sold.
Let’s revisit the initial research question. We are interested in the effect a price reduction has on sales. We can express it as either
the effect of \(T\) on \(Y\)
the is_on_sale on weekly_amount_sold.
Fundamental problem of causal inference
To compute the effect, we would ideally know for each observation the counterfactual outcome, i.e. if it was on sale, how would have been sales if it was not on sales or if it was not on sale, how would have been sales if it was on sale? However, due to the fundamental problem of causal inference, it is impossible to observe both states.
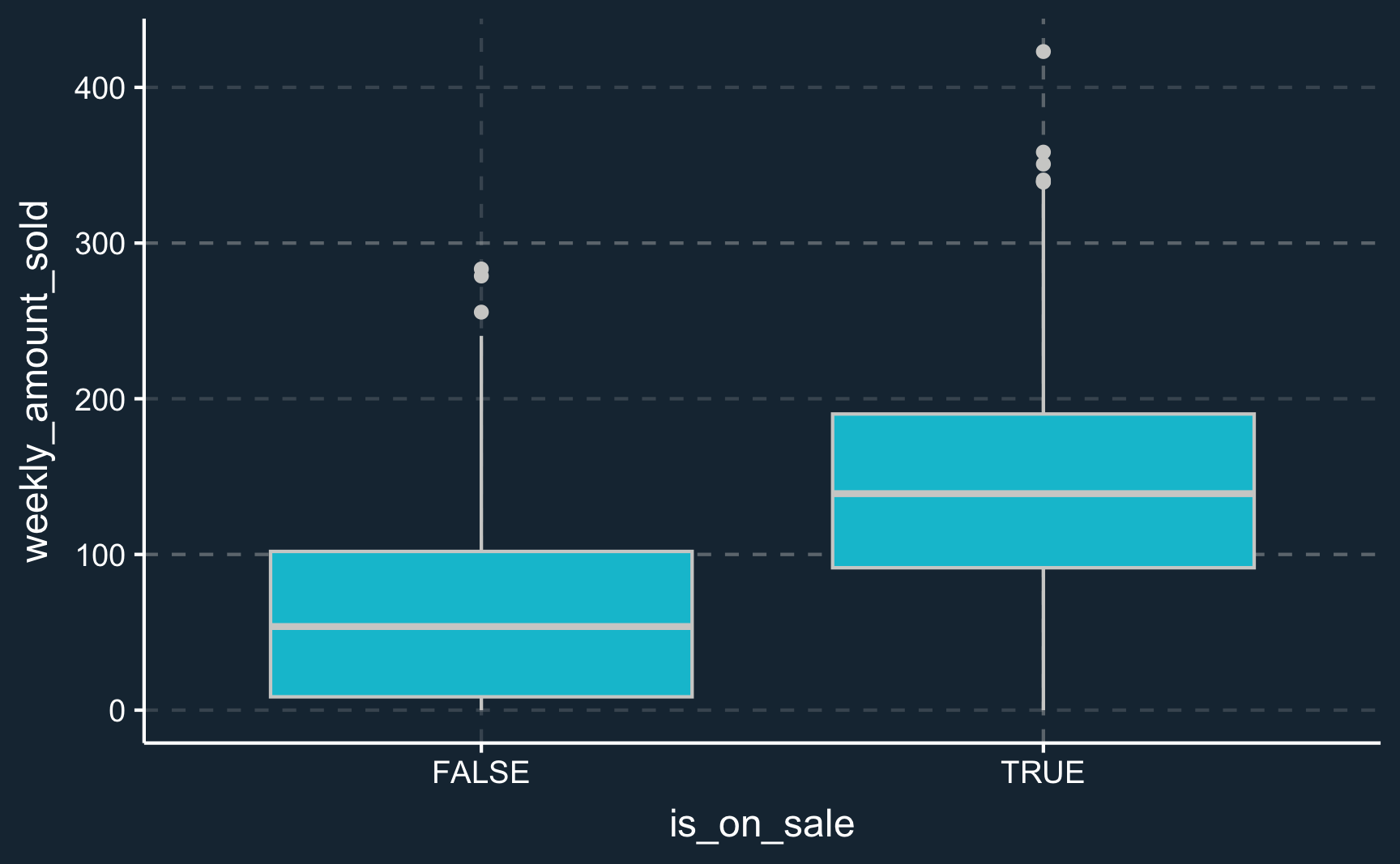
Therefore, at first, you are often tempted to compare the observations that were on sale (“treated”) with the observations that were not on sale (“control”). Because that’s easy to calculate, let’s plot the result. A good way to compare and plot observations of two groups is a box plot.
Note
For plots, we make use of the package ggplot2 which is included in the tidyverse you already loaded. Both plots show the same data and convey the same message, but because ggplot2 is a package dedicated to data visualization it has some advantages regarding aesthetics and the efficiency in creating plots.
If you are interested in an introduction to ggplot2, I recommend this resource written by Megan Hall.
By the way, don’t be confused when your plot appears different in terms of colors, fonts etc. compared to the one shown here. It is adjusted to match the website theme.
# Box plot in base R# boxplot(weekly_amount_sold ~ is_on_sale, data = sales)# Box plot in ggplot2ggplot( data =sales, # first, provide the dataaes(# then, provide the aesthetics (at least X and Y) x =is_on_sale, y =weekly_amount_sold))+geom_boxplot()# with a "+" add what type of plot
What do we see? Stores that dropped their prices sell more. It confirms our intuition that people buy more on sale. However, the difference seems very high. Let’s calculate it.
Note
To access a data frame, there are several ways in R. In the following chapters, we will use other ways to extract data but here we use the following syntax: dataframe[condition, ]$column. First you take the data frame that contains the data you want to extract or subset. Then you provide a condition on how to subset. If you just want to have a specific column, you can extract it using the $ operator. Please note that if your condition refers to a column in the same data frame, you need to call the data frame another time like dataframe$filter_column.
To compute the average of a column (or more precise: a vector), we use the function mean().
For printing several variables, in notebooks, you can just collect them in a vector by c(var1, var2, ...). If you want to name the elements provide a name in quotation marks: c("name1" = var1, ...).
# Outcome for all observations on saleY1<-sales[sales$is_on_sale==TRUE, ]$weekly_amount_soldY1_mean<-mean(Y1)# Outcome for all observations not on saleY0<-sales[sales$is_on_sale==FALSE, ]$weekly_amount_soldY0_mean<-mean(Y0)# Show both outcomes and their differencec("Avg. outcome on sale"=Y1_mean,"Avg. outcome not on sale"=Y0_mean,"Difference"=Y1_mean-Y0_mean)
Avg. outcome on sale Avg. outcome not on sale Difference
141 63 78
The difference is even higher than the outcome for stores that did not implement a sales campaign. At this point, the alarm bells should ring - a simple comparison is very unlikely to yield a valid result.
Question: What explanations can you think of that distort the relationship between the treatment variable and the outcome? Think back to what has been discussed in the lecture.
Answer
There might be one or several common causes (confounders). Two causes that affect both is_on_sale and weekly_amount_sold are the (1) business size (or: avg_week_sales) and the (2) time distance to Christmas (weeks_to_xmas). Because (1) larger businesses are more likely to implement sales campaigns and naturally sell more and because (2) sales are often implemented close to Christmas when customers buy anyway.
Summarizing, there is no way to know the true causal effect of price cuts on units sold as we do not observe both worlds for all units: the world with price cuts and the world without price cuts. That’s what the fundamental problem of causal inference states. Throughout the whole course, we will come up with ways and methods to deal with this problem and get as close to the causal effect as possible.
Unrealistic scenario
For now, let’s imagine the impossible and assume we can actually see both worlds and know both states for each observation. In potential outcomes (PO) notation, that means we can see both \(Y_{i1}\) and \(Y_{i0}\), where \(0\) and \(1\) refer to the treatment states for unit \(i\).
\[
Y_i=\begin{cases}Y_{i1} \ \text{if unit i received treatment}\\Y_{i0} \ \text{otherwise}\\\end{cases}
\]
When you take a look at the table, you see the observed outcome y and both potential outcomes y0 and y1, one of which is the observed and the other one the counterfactual outcome. You also see a store identifier, the treatment status t, a covariate x and the individual treatment effect (\(ITE\)) te.
# Read data "unrealistic" scenariosales_unreal<-read_csv("sales_unreal.csv")# Print tableprint(sales_unreal)
In this unrealistic scenario, knowing all states, it is easy to compute the average treatment effect (\(ATE\)). For each unit, we subtract the untreated outcome from the treated outcome and take the average. Or even easier, because there are already computed ITEs in the data, we take the average of those.
ATE<-mean(sales_unreal$y1-sales_unreal$y0)# equivalent to: mean(sales_unreal$te)ATE
[1] 65
The true average causal treatment effect is 65. In formula notation, we calculated the sample equivalent of
Without any problems, you could also calculate the conditional average treatment effect (\(CATE\)), i.e. the average treatment effect for units where the \(X\) takes on the specified value \(x\).
\[
CATE = E[Y_{i1} - Y_{i0} | X = x]
\]
Realistic scenario
But now let’s get back to the actual scenario: we just observe one outcome and we do not what would have happened in a different world. Consequently, the data looks like this:
# A tibble: 6 × 7
i y0 y1 t x y te
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <lgl>
1 1 200 NA 0 0 200 NA
2 2 120 NA 0 0 120 NA
3 3 300 NA 0 1 300 NA
4 4 NA 500 1 0 500 NA
5 5 NA 600 1 0 600 NA
6 6 NA 800 1 1 800 NA
Remember, the true causal effect is 65. Let’s check, how close we get when we try to estimate the ATE by comparing the treated observations to the untreated observations.
# Average outcome for treated observationsy1<-mean(sales_real[sales_real$t==1, ]$y)# Average outcome for not treated observationsy0<-mean(sales_real[sales_real$t==0, ]$y)# Show both outcomes and their differencec("Avg. treated outcomes"=y1,"Avg. not treated outcomes"=y0,"Difference"=y1-y0)
It’s \(426.667\) and thus very far off. Again, it proves the danger of taking naive averages and the inequality of association and causation. The reason here is that businesses engaged in sales are different from those that did not and would have sold more regardless of price cut.
Bias
The difference is also called bias and with full knowledge of all states can be calculated by:
You see that there is a bias when \(E[Y_0|D=1]\) is not equal to \(E[Y_0|D=1]\). That means, for no bias to occur, treated and untreated units only differ in their treatment status and is called the ignorability or exchangeability assumption.
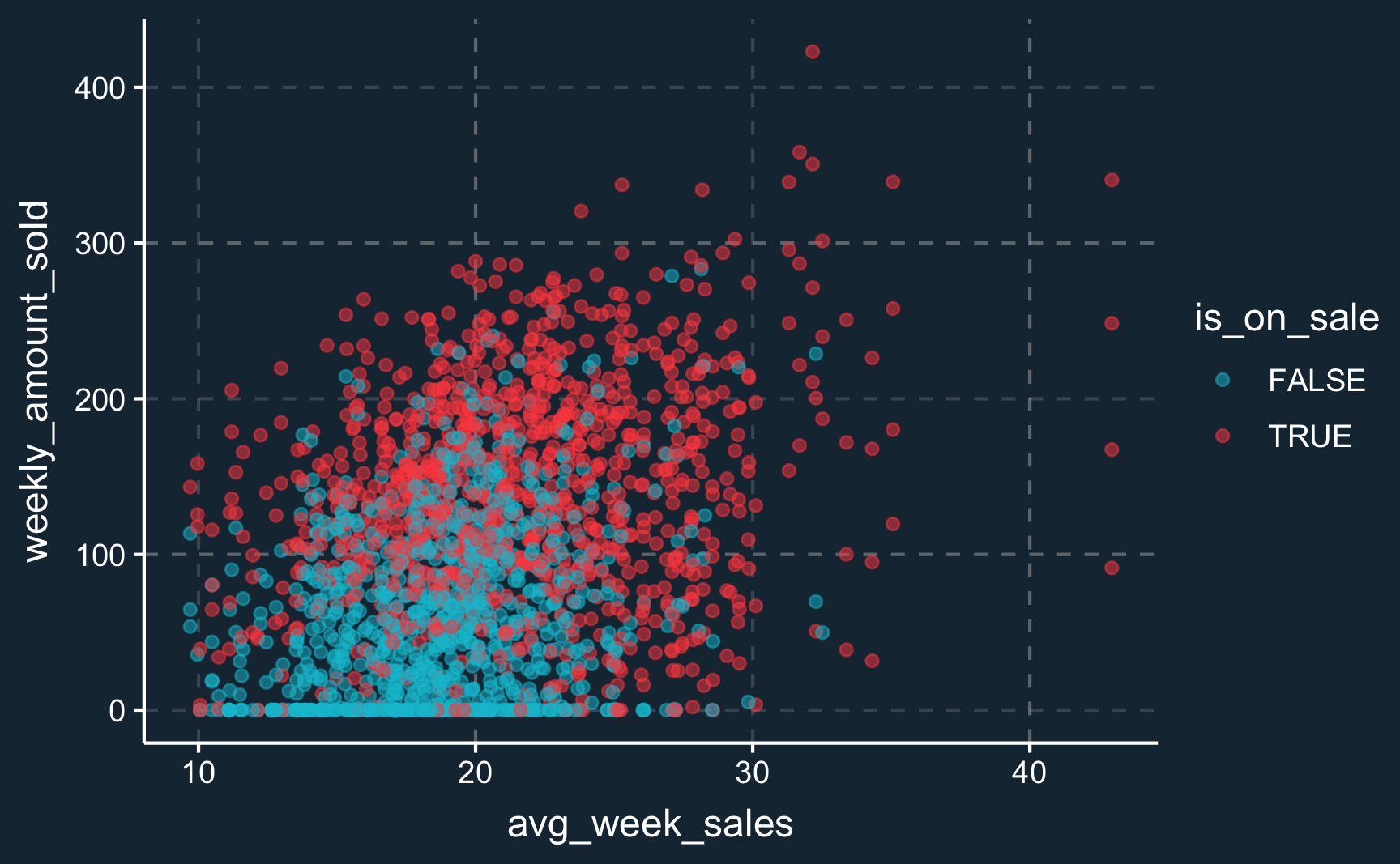
Going back to the dataset with many observations, what can you infer from this plot? Does the plot indicate any violations of the assumptions?
# Plot business size vs outcomeggplot( data =sales,aes(x =avg_week_sales, y =weekly_amount_sold, color =is_on_sale)# different color depending on value of 'is_on_sale')+geom_point(alpha =.5)# with alpha, we control point transparency
Warning: The `scale_name` argument of `discrete_scale()` is deprecated as of ggplot2 3.5.0.
Assignment
Make sure you went through all organizational steps and have accepted the Week 1 - Assignment, which you will re-upload to GitHub Classroom via GitHub Desktop after solving the following questions.
[DEADLINE: Monday, 22 April 23:59]
What is 1+1 ? [Example question to test GitHub upload]
What is 2+2 ? [Example question to test GitHub upload]
Go to the unrealistic scenario where you know all states and have all data at your hand.
Compute the \(CATE\) for all observed values of \(X\). Check if there are any differences and explain the meaning of a \(CATE\) compared to an \(ATE\).
Compute the bias with the given formula and explain whether it is an upward or a downward bias.
For the Christmas sales data:
Discuss the assumptions you have learned in the lecture and argue what assumptions are likely to hold or to be violated. The assumptions are:
Just by looking at the last plot, find an interval with good overlap and balance between treated and untreated units and compute an average treatment effect for this interval.