Code
#df <- readRDS("~/my_drive/02_TUHH/03_github/causal_ds_ss24/content/course_weeks/week_08/rand_enc_w8.rds")Due to an unexpected scheduling conflict, we have to cancel today’s lecture (17 June). Instead, the lecture will take place tomorrow (18 June) from 15:00 to 16:30 in room O-0.007. Following the lecture, the tutorial will be held from 16:45 to 18:15 in room A-0.19.
Sorry for the inconvenience. See you tomorrow!
Before start, please fill out course evaluation.
This week, we will do a recap of topics from week 5, week 6 and week 7. More precisely, the focus of this week’s tutorial will be on:
Let’s directly start using the following data set. Data very similar to what we have used last week but extended by a few covariates. For now, ignore the instrument popup, which you will need for your assignment.
#df <- readRDS("~/my_drive/02_TUHH/03_github/causal_ds_ss24/content/course_weeks/week_08/rand_enc_w8.rds")We’ll follow the general recipe for double machine learning from the lecture to estimate the average treatment effect using augmented inverse probability weighting (AIPW). It splits the process into four steps:
In the first step, we have to find the Neyman orthogonal score, which is
\[ \mathbb{E} \left[ \mu(1, X) - \mu(0, X) + \frac{T(Y - \mu(1,X))}{e(X)} - \frac{(1 - T)(Y - \mu(0, X))}{1 - e(X)} - \tau_{ATE} \right] = 0. \] We can already see that there are three nuisance parameters we need to fit and predict, given by the set \(\eta\).
\[ \begin{align*} \eta &= (\mu(1, X), \mu(0, X), e(X)), \, \text{where} \\ \mu(t,X) :&= \mathbb{E}[Y \mid T = t, X] \\ e(X) :&= \mathbb{E}[T=1 \mid X] \end{align*} \]
Like before, we are going to use the mlr3 environment and code all steps by hand. Let’s load the packages and define outcome and treatment.
library(mlr3)
library(mlr3learners)
# Outcome
Y <- df$time_spent
# Treatment
D <- df$used_ftrOne key element of double machine learning is cross-fitting. So let’s create folds and assign each unit to one fold. Units from one particular fold will be predicted based on a model fitted on all other units.
Fold by fold, we will go through the prediction process. Therefore, we first initialize empty nuisance vectors to be populated.
Now we can specify the models we want to use. The advantage of double machine learning is that we can choose from a wide range of flexible estimators to address non-linearities etc. E.g. the estimators classif.ranger and regr.ranger are random forests which have proven to show very good prediction performance.
Task 1: Complete the code.
# Define prediction model for the treatment/exposure
task_e <- ...
lrnr_e <- ...
# Define prediction model for the outcome
task_mu <- ...
lrnr_mu <- ...# Define prediction model for the treatment/exposure
task_e <- as_task_classif(df |> select(-time_spent, -popup), target = "used_ftr")
lrnr_e <- lrn("classif.ranger", predict_type = "prob")
# Define prediction model for the outcome
task_mu <- as_task_regr(df |> select(-used_ftr, -popup), target = "time_spent")
lrnr_mu <- lrn("regr.ranger", predict_type = "response")Now, we will loop through the estimation procedure to obtain estimated nuisance parameters for all units.
for loop
A for loop in R is a control flow statement that allows code to be executed repeatedly based on a sequence of values, iterating over each element in a vector or list. It is commonly used for performing repetitive tasks efficiently.
Task 2: Complete the code.
# cross fitting of nuisance parameters
for (i in 1:nfolds){
print(paste("Fold", i, "..."))
# propensity score e(x)
lrnr_e$train(task_e, row_ids = which(fold != i))
ehat[which(fold == i)] <- lrnr_e$predict(task_e, row_ids = which(fold == i))$prob[, 2]
# outcome mu(0,x)
lrnr_mu$train(task_mu, row_ids = intersect(which(fold != i), which(df$used_ftr == 0)))
muhat0[which(fold == i)] <- lrnr_mu$predict(task_mu, row_ids = which(fold == i))$response
# outcome mu(1,x)
lrnr_mu$train(task_mu, row_ids = intersect(which(fold != i), which(df$used_ftr == 1)))
muhat1[which(fold == i)] <- lrnr_mu$predict(task_mu, row_ids = which(fold == i))$response
}[1] "Fold 1 ..."
[1] "Fold 2 ..."
[1] "Fold 3 ..."
[1] "Fold 4 ..."
[1] "Fold 5 ..."For the third step, solving for our target parameter, we obtain:
\[ \begin{align*} \mathbb{E} \left[ \mu(1, X) - \mu(0, X) + \frac{T(Y - \mu(1, X))}{e(X)} - \frac{(1 - T)(Y - \mu(0, X))}{1 - e(X)} - \tau_{\text{ATE}} \right] &= 0 \\ \tau_{\text{ATE}} \underbrace{(-1)}_{\psi_a} + \mathbb{E} \bigg[ \underbrace{\mu(1, X) - \mu(0, X) + \frac{T(Y - \mu(1, X))}{e(X)} - \frac{(1 - T)(Y - \mu(0, X))}{1 - e(X)}}_{\psi_b} \bigg] &= 0 \\ \Rightarrow \tau_{\text{ATE}} = -\frac{\mathbb{E}[\psi_b(W; \eta)]}{\mathbb{E}[\psi_a(W; \eta)]} = \mathbb{E} \left[ \mu(1, X) - \mu(0, X) + \frac{T(Y - \mu(1, X))}{e(X)} - \frac{(1 - T)(Y - \mu(0, X))}{1 - e(X)} \right] \end{align*} \]
For this particular method, obtaining \(\psi_a\) is quite simple.
But what about \(\psi_b\)? That’s quite a long mathematical expression. Let’s break it down.
\[ \tau_{\text{ATE}} = -\frac{\mathbb{E}[\psi_b(W; \eta)]}{\mathbb{E}[\psi_a(W; \eta)]} = \mathbb{E} \left[ {\color{#FF7E15}\mu(1, X) - \mu(0, X)} + \frac{T(Y - \mu(1, X))}{e(X)} - \frac{(1 - T)(Y - \mu(0, X))}{1 - e(X)} \right] \]
Task 3a: Complete the code.
psi_b_mu <- ...psi_b_mu <- muhat1 - muhat0\[ \tau_{\text{ATE}} = -\frac{\mathbb{E}[\psi_b(W; \eta)]}{\mathbb{E}[\psi_a(W; \eta)]} = \mathbb{E} \left[ \mu(1, X) - \mu(0, X) + {\color{#FF7E15}\frac{T(Y - \mu(1, X))}{e(X)}} - \frac{(1 - T)(Y - \mu(0, X))}{1 - e(X)} \right] \]
Task 3b: Complete the code.
psi_b_res1 <- ...psi_b_res1 <- D * (Y - muhat1) / ehat\[ \tau_{\text{ATE}} = -\frac{\mathbb{E}[\psi_b(W; \eta)]}{\mathbb{E}[\psi_a(W; \eta)]} = \mathbb{E} \left[ \mu(1, X) - \mu(0, X) + \frac{T(Y - \mu(1, X))}{e(X)} - {\color{#FF7E15}\frac{(1 - T)(Y - \mu(0, X))}{1 - e(X)}} \right] \]
Task 3c: Complete the code.
psi_b_res0 <- ...psi_b_res0 <- (1 - D) * (Y - muhat0) / (1 - ehat)Bringing it back together, \(\psi_a\) obtains as
Task 3d: Complete the code.
psi_b <- ...psi_b <- psi_b_mu + psi_b_res1 - psi_b_res0and \(\tau_{\text{ATE}} = -\frac{\mathbb{E}[\psi_b(W; \eta)]}{\mathbb{E}[\psi_a(W; \eta)]}\) as
Task 3e: Complete the code.
tau <- ...In the fourth step, compute statistical information such as standard errors. It is a bit cumbersome which is why I summarized it into a function. But feel free to check the details in the lecture slides.
summary_dml <- function(psi_a, psi_b) {
# compute ATE
tau <- -sum(psi_b) / sum(psi_a)
# compute variance
psi <- tau * psi_a + psi_b
Psi <- - psi / mean(psi_a)
sigma2 <- var(Psi)
# standard error
se <- sqrt(sigma2 / n)
# t-statistic and p-value
se <- sqrt(sigma2 / n)
t <- tau / se
p <- 2 * pt(abs(t), n ,lower = FALSE)
# bind together
return(data.frame(tau = round(tau, 3), t = round(t, 3), se = round(se, 3), p = round(p, 5)))
}Apply function to our estimated vectors.
# Inference
tau_stats <- summary_dml(psi_a, psi_b)
print(tau_stats) tau t se p
1 9 20 0.45 0Of course, there is a faster and more flexible approach than the manual coding. In just a couple of steps, using Double_ML package, you will get the same result and there is less risk of including errors due to e.g. confusing indices etc.
Task 4: Complete the code.
# Load required packages
library(DoubleML)
# suppress messages during fitting
lgr::get_logger("mlr3")$set_threshold("warn")
# Specify data object
# ...
# Specify task
# ...
# Fit
# ...
# Return summary
# ...# Load required packages
library(DoubleML)
# suppress messages during fitting
lgr::get_logger("mlr3")$set_threshold("warn")
# Specify data object
dml_data <- DoubleMLData$new(
data = as.data.frame(df),
y_col = "time_spent",
d_cols = "used_ftr",
x_cols = c("age", "gender", "premium", "daily_logins")
)
# Specify task
dml_aipw_obj = DoubleMLIRM$new(
data = dml_data,
ml_g = lrnr_mu,
ml_m = lrnr_e,
score = "ATE",
trimming_threshold = 0.01, # to prevent too extreme weights
apply_cross_fitting = TRUE,
n_folds = 5)
# Fit and return summary
dml_aipw_obj$fit()
dml_aipw_obj$summary()Estimates and significance testing of the effect of target variables
Estimate. Std. Error t value Pr(>|t|)
used_ftr 9.170 0.448 20.5 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1While we have estimated the average treatment effect, now we would like to estimate who would benefit from the treatment. To be more precise, who should we make sure to use the new feature? That is what policy learning is about. It yields a personalized treatment recommendation.
Mathematically, we want to find optimal policy \(\pi^*\) that maximizes \(Q(\pi) := \mathbb{E}[Y_i(\pi(\mathbf{X_i}))]\). Based on the covariates, we decide whether a unit is assigned to the treatment or to the control group and in such a way that the each unit receives the best treatment or consequently that total effects are as large as possible.
With some re-arrangements and by comparing the policy against random policy, we get the optimization function with the desired properties. It shows that we need to “get right for those with biggest CATEs”. Because for each unit wrongly assigned, we lose or earn absolute value of its CATE.
\[ \hat{\pi} = \underset{\pi \in \Pi}{\arg \max} \left\{ \frac{1}{N} \sum_{i=1}^N \overbrace{|\tilde{\tau_i}_{\text{ATE}}^{\text{AIPW}}|}^{\text{weight}} \underbrace{\operatorname{sign}(\tilde{\tau_i}_{\text{ATE}}^{\text{AIPW}})}_{\text{to be classified}} \overbrace{(2\pi(X_i) - 1)}^{\text{function to be learned}} \right\} \]
However, due to the fundamental problem of causal inference, we do not know the CATEs beforehand. Therefore, we use \(\tilde{\tau_i}_{\text{ATE}}^{\text{AIPW}}\) as an approximation. We add the needed terms to our data.
# Approximation of individual treatment effects
ite_pseudo <- dml_aipw_obj$psi_b[, 1, 1]
# Add weight and class (1 or -1) to data
df_pl <- df |>
select(-popup, -used_ftr, -time_spent) |>
add_column(sign = sign(ite_pseudo)) |>
add_column(weight = abs(ite_pseudo))Then, we can simplify the expression from above and see we are left with a binary weighted classification problem and can use methods like decision trees/forests, logistic lasso, SVM etc. See here for a full overview of learners. The outcome in the classification problem is \(\operatorname{sign}(\tilde{\tau_i}_{\text{ATE}}^{\text{AIPW}})\), the covariates are \(X_i\) and the weights are \(|\tilde{\tau_i}_{\text{ATE}}^{\text{AIPW}}|\).
Task 3e: Complete the code.
## Specify task
# Task
# ...
# Assign weight column
# ...
# Specify learner
# ...
# Train
# ...
# Predict classes
# ...## Specify task and learner
# Task
task_pl <- as_task_classif(df_pl, target = "sign")
# Assign weight column
task_pl$set_col_roles(col = "weight", roles = "weight")
# Specify learner
lrnr_pl <- lrn("classif.xgboost")
# Train
lrnr_pl$train(task_pl)
# Predict classes
pl_class <- lrnr_pl$predict(task_pl)$response
summary(pl_class) -1 1
26 9974 Let’s add the recommended class to our data and check how the units assigned to different classes differ in regard to their characteristics.
# Add to data frame
df_pl$rec_class <- pl_class
# Average values by recommended class (like CLAN)
df_pl_CLAN <- df_pl |>
group_by(rec_class) |>
summarise(
age = mean(age),
gender = mean(gender),
premium = mean(premium),
logins = mean(daily_logins)
) |>
ungroup()
# Print
print(df_pl_CLAN)# A tibble: 2 × 5
rec_class age gender premium logins
<fct> <dbl> <dbl> <dbl> <dbl>
1 -1 33.4 0.385 0.115 2.85
2 1 29.2 0.501 0.207 2.66# Plot CLAN
df_pl_CLAN |>
pivot_longer(cols = -rec_class) |>
ggplot(aes(x = rec_class, y = value)) +
geom_bar(stat = "identity") +
facet_wrap(~name, scales = "free")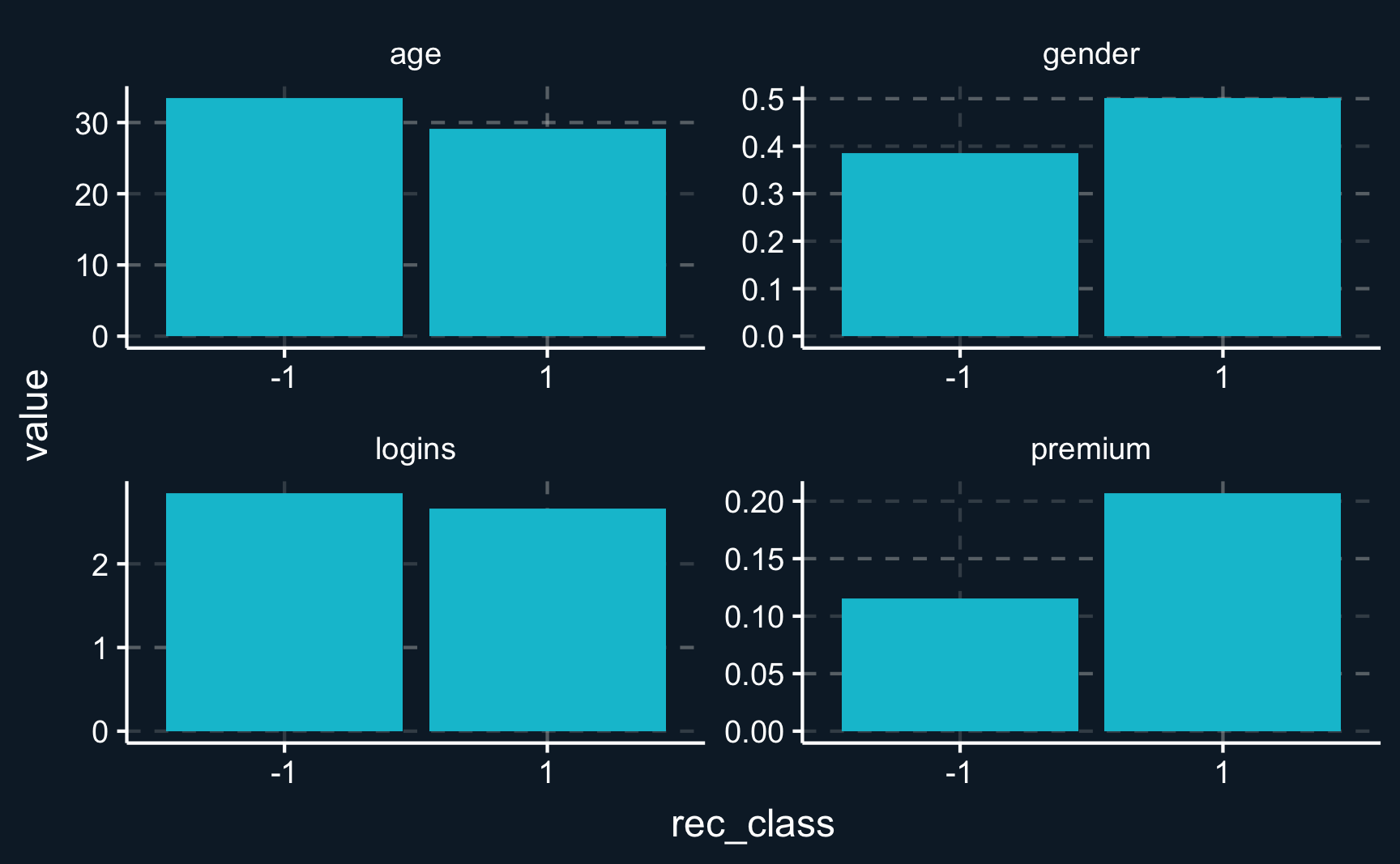
For this week’s assignment, you’ll be asked to perform an instrumental variable estimation. You’ll need the following nuisance parameters
\[ \quad \mu(Z_i, \mathbf{X_i}) = \mathbb{E}[Y_i \mid Z_i, \mathbf{X_i}] \quad \quad \quad e(\mathbf{Z_i, X_i}) = P[T_i \mid Z_i, \mathbf{X_i}] \quad \quad \quad h(\mathbf{X_i}) = P[Z_i \mid \mathbf{X_i}] \]
and the moment condition of Neyman-orthogonal score
\[ \begin{align} \mathbb{E}[\psi_b] + \mathbb{E}[\psi_a] \cdot \tau_{\text{LATE}} = &\mathbb{E}\bigg[\mu(1, \mathbf{X_i}) - \mu(0, \mathbf{X_i}) + \frac{Z_i(Y_i - \mu(1, \mathbf{X_i}))}{h(\mathbf{X_i})} - \frac{(1-Z_i)(Y_i - \mu(0, \mathbf{X_i})}{(1-h(\mathbf{X_i}))} \bigg] \\ &+ \mathbb{E}\bigg[(-1)\left[e(1, \mathbf{X_i}) - e(0, \mathbf{X_i}) + \frac{Z_i(T_i - e(1, \mathbf{X_i}))}{h(\mathbf{X_i})} - \frac{(1-Z_i)(T_i - e(0, \mathbf{X_i})}{(1-h(\mathbf{X_i}))}\right] \bigg] \cdot \tau_{\text{LATE}} = 0. \end{align} \]
Accept the Week 8 - Assignment and follow the same steps as last week and as described in the organization chapter.
Please also remember to fill out the course evaluation if you have not done so already.
Using the data from the tutorial include the instrument popup and compute the local average treatment effect (LATE) using interactive (AIPW) instrumental variable estimation. Follow the general recipe and answer the following questions. (You can choose any learner available in the mlr3 environment.)
What nuisance parameters do you need to estimate? Answer in the following style: “Regress … on … conditional on …”.
Plug your estimates in to the moment condition of the Neyman-orthogonal score to retrieve the estimate.
Additionally, perform the estimation using the DoubleML package.
Compare the estimates to the estimate obtained in the tutorial.
Having obtained a pseudo outcome in the previous steps, use it to do offline policy learning with a decision tree lrn("classif.rpart").
Consider the following restriction: for the treatment effect to be beneficial for an individual, he/she needs to spend at least two more times on the app. Put differently, the cost of the treatment can be translated to two minutes. Integrate this restriction into your problem and train the decision tree.
Use the function rpart.plot() from the rpart.plot package to interpret the result. Describe what you can infer from the plot.