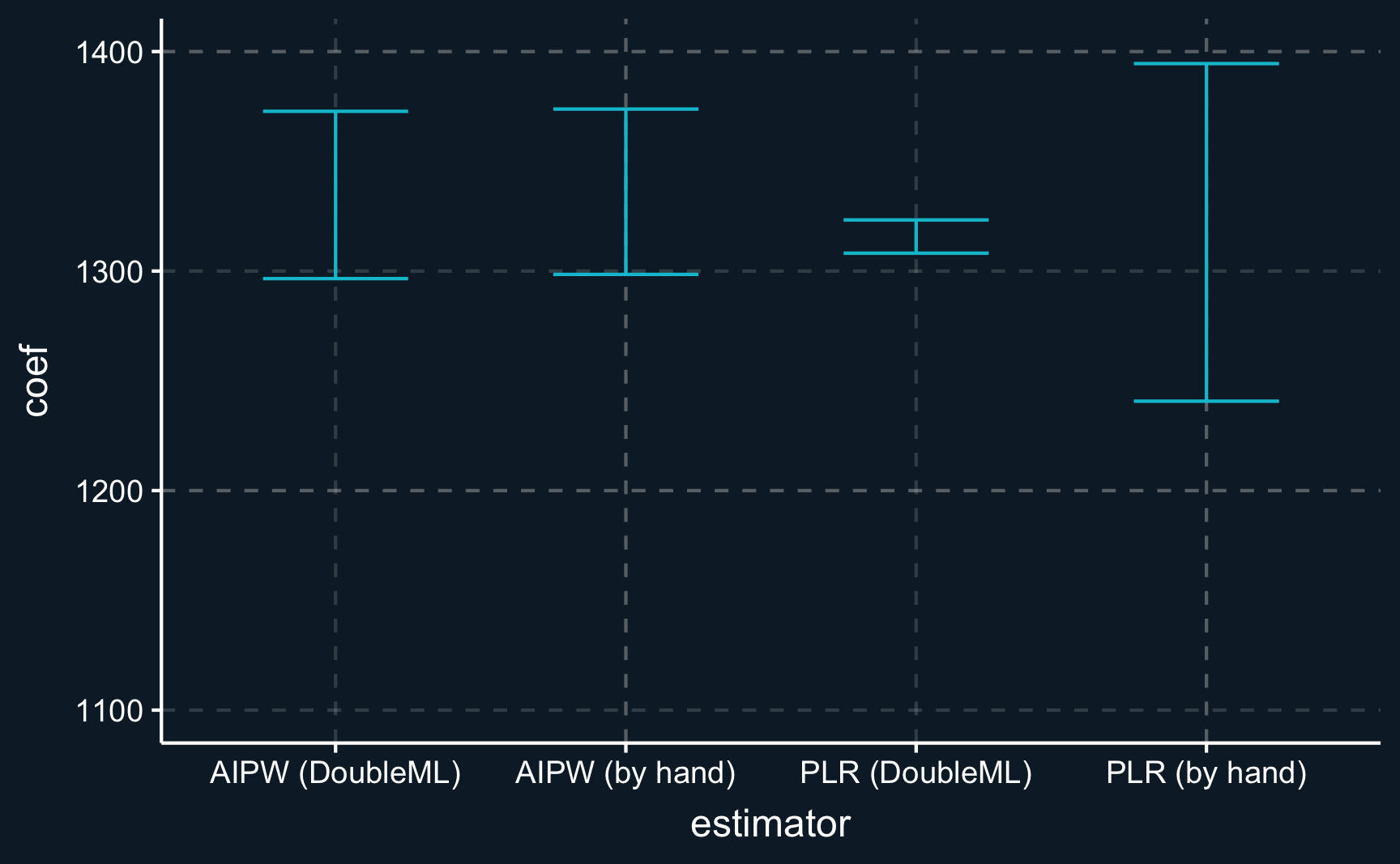
Rows: 10,000
Columns: 27
$ mkt_email <dbl> 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0…
$ next_mnth_pv <dbl> 1764.62, 162.21, 42.33, 12.41, 1398.49, 1088.87, 1485.70, 812.83, 1091.01, 2081.43, 984.25, 1755.68, 1.75, 1525.07, 739.7…
$ age <dbl> 34, 65, 26, 31, 36, 68, 27, 23, 46, 27, 35, 37, 30, 31, 24, 29, 23, 49, 46, 28, 49, 47, 34, 41, 42, 24, 28, 34, 55, 27, 3…
$ tenure <dbl> 2, 0, 1, 0, 2, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 2, 0, 0…
$ ammount_spent <dbl> 230.31, 142.41, 103.19, 10.25, 30.34, 78.16, 178.64, 37.14, 182.87, 136.78, 4.75, 28.81, 0.68, 92.45, 40.65, 192.17, 186.…
$ vehicle <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0…
$ food <dbl> 2, 2, 0, 0, 1, 2, 0, 1, 0, 1, 1, 1, 0, 1, 2, 0, 0, 2, 0, 2, 1, 1, 3, 1, 4, 1, 0, 1, 2, 0, 0, 1, 0, 2, 1, 1, 1, 0, 2, 1, 1…
$ beverage <dbl> 2, 3, 0, 1, 0, 0, 1, 0, 0, 2, 1, 1, 0, 0, 1, 3, 0, 0, 1, 0, 1, 1, 1, 0, 1, 2, 1, 0, 2, 2, 2, 1, 0, 2, 1, 0, 3, 1, 0, 0, 0…
$ art <dbl> 1, 0, 1, 0, 0, 0, 2, 0, 2, 3, 0, 0, 3, 0, 1, 3, 0, 0, 4, 2, 2, 1, 1, 1, 1, 1, 2, 1, 0, 0, 0, 0, 2, 0, 2, 0, 1, 1, 1, 2, 0…
$ baby <dbl> 0, 3, 2, 1, 1, 1, 1, 2, 1, 0, 1, 0, 3, 0, 0, 1, 1, 2, 1, 1, 1, 0, 2, 1, 1, 4, 1, 3, 1, 3, 2, 1, 3, 1, 0, 0, 2, 2, 3, 1, 2…
$ personal_care <dbl> 2, 0, 0, 1, 0, 0, 2, 0, 2, 1, 3, 1, 2, 2, 1, 2, 3, 2, 1, 0, 0, 1, 1, 2, 0, 0, 1, 2, 0, 0, 0, 4, 1, 0, 1, 2, 2, 1, 0, 0, 2…
$ toys <dbl> 0, 1, 2, 0, 0, 0, 1, 1, 1, 2, 0, 2, 0, 0, 1, 0, 0, 0, 0, 1, 2, 3, 0, 1, 2, 0, 3, 1, 1, 0, 1, 0, 0, 0, 1, 2, 1, 0, 0, 1, 1…
$ clothing <dbl> 1, 3, 4, 1, 1, 4, 2, 1, 1, 4, 2, 2, 2, 3, 1, 0, 1, 0, 2, 2, 1, 0, 0, 1, 1, 3, 0, 3, 3, 1, 0, 6, 3, 0, 3, 8, 7, 3, 2, 1, 1…
$ decor <dbl> 0, 0, 1, 2, 1, 0, 1, 1, 0, 1, 2, 5, 1, 2, 0, 1, 0, 2, 0, 1, 3, 0, 2, 0, 0, 0, 0, 1, 0, 3, 0, 1, 1, 0, 3, 0, 0, 0, 0, 0, 2…
$ cell_phones <dbl> 4, 1, 2, 3, 3, 1, 5, 1, 3, 4, 0, 3, 1, 3, 2, 0, 1, 1, 4, 3, 1, 2, 1, 4, 2, 6, 3, 5, 3, 1, 2, 1, 5, 4, 6, 3, 5, 2, 1, 3, 4…
$ construction <dbl> 3, 1, 0, 1, 2, 1, 0, 1, 1, 0, 2, 2, 1, 1, 2, 2, 2, 0, 2, 1, 2, 0, 1, 0, 2, 2, 0, 2, 1, 0, 1, 1, 1, 2, 1, 0, 3, 0, 2, 0, 0…
$ home_appliances <dbl> 0, 1, 1, 2, 1, 1, 1, 0, 1, 1, 2, 2, 2, 3, 1, 0, 1, 0, 0, 1, 1, 2, 0, 2, 0, 0, 1, 0, 2, 1, 1, 2, 2, 3, 2, 0, 1, 1, 2, 0, 1…
$ electronics <dbl> 2, 4, 2, 1, 4, 0, 0, 3, 1, 5, 0, 5, 0, 4, 2, 2, 2, 3, 1, 3, 1, 1, 3, 1, 1, 2, 4, 2, 3, 3, 2, 2, 1, 1, 0, 1, 0, 1, 1, 3, 3…
$ sports <dbl> 0, 3, 1, 0, 0, 1, 0, 2, 2, 1, 1, 0, 0, 1, 1, 0, 0, 1, 2, 1, 0, 0, 1, 0, 1, 0, 0, 1, 2, 1, 0, 0, 3, 0, 2, 0, 2, 0, 1, 1, 2…
$ tools <dbl> 0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 2, 0, 0, 3, 0, 1, 0, 3, 0, 4, 1, 0, 1, 0, 1, 0, 2, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0…
$ games <dbl> 2, 3, 2, 0, 1, 2, 2, 0, 2, 1, 2, 1, 2, 3, 2, 1, 2, 1, 5, 2, 1, 2, 1, 0, 3, 4, 3, 0, 2, 1, 1, 0, 1, 3, 1, 0, 1, 2, 1, 0, 4…
$ industry <dbl> 0, 1, 2, 0, 3, 1, 4, 1, 1, 2, 1, 1, 0, 1, 0, 2, 0, 1, 1, 0, 0, 0, 1, 2, 0, 0, 0, 1, 4, 0, 0, 0, 0, 0, 1, 1, 3, 2, 1, 2, 2…
$ pc <dbl> 2, 3, 5, 2, 0, 3, 3, 2, 2, 3, 3, 4, 3, 2, 0, 1, 0, 2, 0, 4, 3, 2, 0, 3, 2, 2, 3, 3, 1, 0, 1, 1, 2, 0, 2, 2, 3, 3, 1, 0, 3…
$ jewel <dbl> 0, 0, 1, 3, 2, 1, 0, 0, 0, 2, 0, 3, 0, 2, 0, 0, 0, 0, 1, 1, 1, 1, 1, 2, 0, 0, 2, 1, 3, 1, 3, 3, 1, 1, 1, 0, 0, 1, 0, 2, 1…
$ books <dbl> 0, 0, 2, 1, 1, 1, 0, 0, 0, 0, 1, 1, 2, 0, 1, 1, 0, 0, 0, 3, 1, 2, 0, 0, 1, 0, 1, 2, 0, 0, 1, 2, 1, 1, 1, 1, 3, 0, 0, 2, 2…
$ music_books_movies <dbl> 3, 2, 1, 2, 0, 3, 1, 0, 1, 0, 1, 0, 3, 2, 1, 1, 0, 1, 3, 0, 0, 1, 0, 1, 1, 1, 1, 2, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 2, 0, 2…
$ health <dbl> 2, 2, 1, 2, 2, 1, 1, 0, 2, 4, 0, 2, 5, 2, 0, 2, 1, 2, 2, 4, 3, 3, 1, 2, 2, 2, 2, 3, 1, 1, 1, 1, 2, 2, 1, 3, 3, 1, 0, 0, 3…