Warning: Paket 'ggplot2' wurde unter R Version 4.3.2 erstelltWarning: Paket 'tidyr' wurde unter R Version 4.3.2 erstelltWarning: Paket 'ggdag' wurde unter R Version 4.3.2 erstellt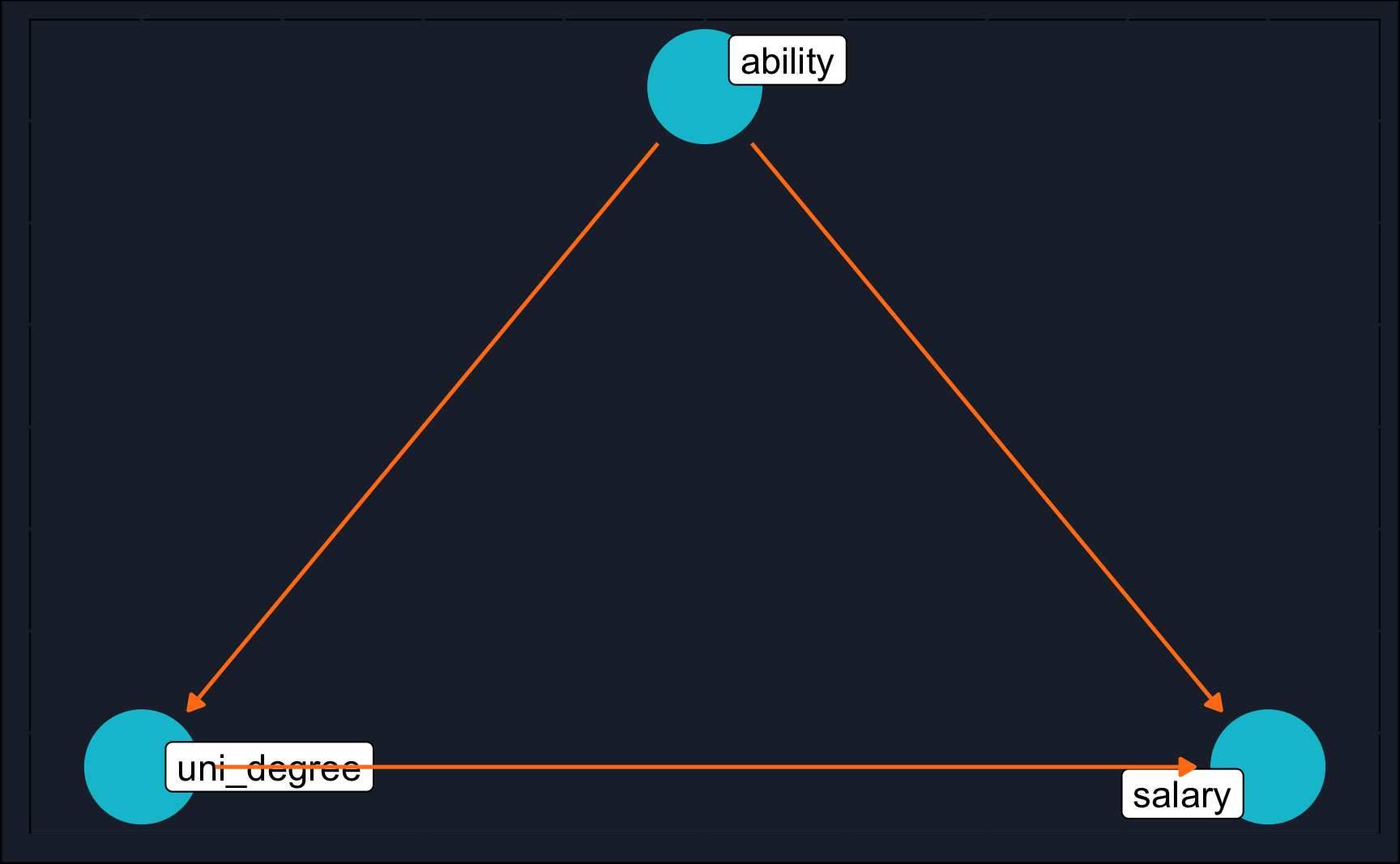
In this chapter, we focus on the identification of causal effects with the help of graphical models, also known as directed acyclic graphs (DAGs). By graphically modeling and leveraging your theoretical knowledge about the data-generating process, you will be able to understand when association is actually causation.
Data-generating process (DGP) refers to the underlying mechanisms that generate the data we observe. It represents real-world processes that produce the data points we analyze.
DAGs show what variables are important for your analysis and how you think they are related. Information to draw a DAG can come from things like:
It should map what you know about the phenomena you are studying into a visual representation. By deciding how to draw your graph you have to ask yourself:
To discuss and illustrate the notation and terminology of DAGs, we start with a simple and often discussed research problem in causal inference. It deals with the question of whether a university degree increases the salary. While people with university degree tend to earn more than people without university degree, there is the question whether this is caused by the university degree or it is mainly influenced by individuals’ ability. People who are more capable tend to go to university and will be more successful in their later career regardless of the university degree. It is very likely that the truth is that both ability and university degree are factors for future salary, but just to get your assumptions clear and guide you in your research strategy, DAGs are of a great benefit. By the way, it helps to imagine association flowing through a graphical model as water flows through a stream.
Depicted in a graph, we get the following:
Warning: Paket 'ggplot2' wurde unter R Version 4.3.2 erstelltWarning: Paket 'tidyr' wurde unter R Version 4.3.2 erstelltWarning: Paket 'ggdag' wurde unter R Version 4.3.2 erstellt
Let’s discuss some terms:
Question 1: What is/are the descendant(s) of ability?
uni_degree and salary
Question 2: What is/are the parent(s) of salary?
uni_degree and ability
Question 3: What is the treatment and what is the outcome?
uni_degree and salary
Question 4: What does a node depict?
A random variable
Question 5: What does an arrow depict?
Flow of association
Of course, it’s perfectly fine to first sketch DAGs on a sheet of paper, but at some point, when your analysis gets more complex, you are well advised to make use of computational resources. In the following paragraphs, you will be introduced to a few very useful resources.
A well implemented application is DAGitty, a browser-based environment for creating and analyzing DAGs. Draw your DAG, define treatment and outcome, which variables are observed and unobserved and many other things. Afterwards, you will see what kind of adjustment is necessary to estimate the causal effect of interest. There is also an implementation in R, which is the R package dagitty complemented by ggdag, which provides improved plotting functionality.
# Install dagitty package
install.packages("dagitty")
# Install ggdag
install.packages("ggdag")Now, we will cover three different ways to create the DAG shown above.
Option 1: Build on browser-based DAGitty
…
Option 2: Build using R package dagitty
In several R functions you will find the syntax y ~ x or y ~ x1 + x2 + ... to specify your functional form. It represents \(y\) being dependent on \(x\) (of course the names depend on your data/model). Please note, that no parentheses are needed.
When drawing the DAG yourself, you can leave out theme_dag_cds() as it is only a custom theme that I have defined for this website. Instead you could use other themes such as theme_dag(), theme_dag_grey(), theme_dag_blank() or proceed without any theme. The other modifications following the theme are also only for the purpose of matching the website theme and can be disregarded. However, you should set text = TRUE in ggdag() in this case.
# Load packages
library(tidyverse)
library(dagitty)
library(ggdag)
# Define dependencies and coordinates
schooling_dag_1 <- dagify(
# Required arguments
uni_degree ~ ability,
salary ~ ability,
salary ~ uni_degree,
# Optional arguments
exposure = "uni_degree",
outcome = "salary",
coords = list(
x = c(uni_degree = 1, salary = 3, ability = 2),
y = c(uni_degree = 1, salary = 1, ability = 2)
))
# Plot DAG
# Plot DAG
ggdag(schooling_dag_1, text = FALSE) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = NA) +
geom_dag_label_repel(aes(label = name), size = 4) +
geom_dag_edges(edge_color = ggthemr::swatch()[7])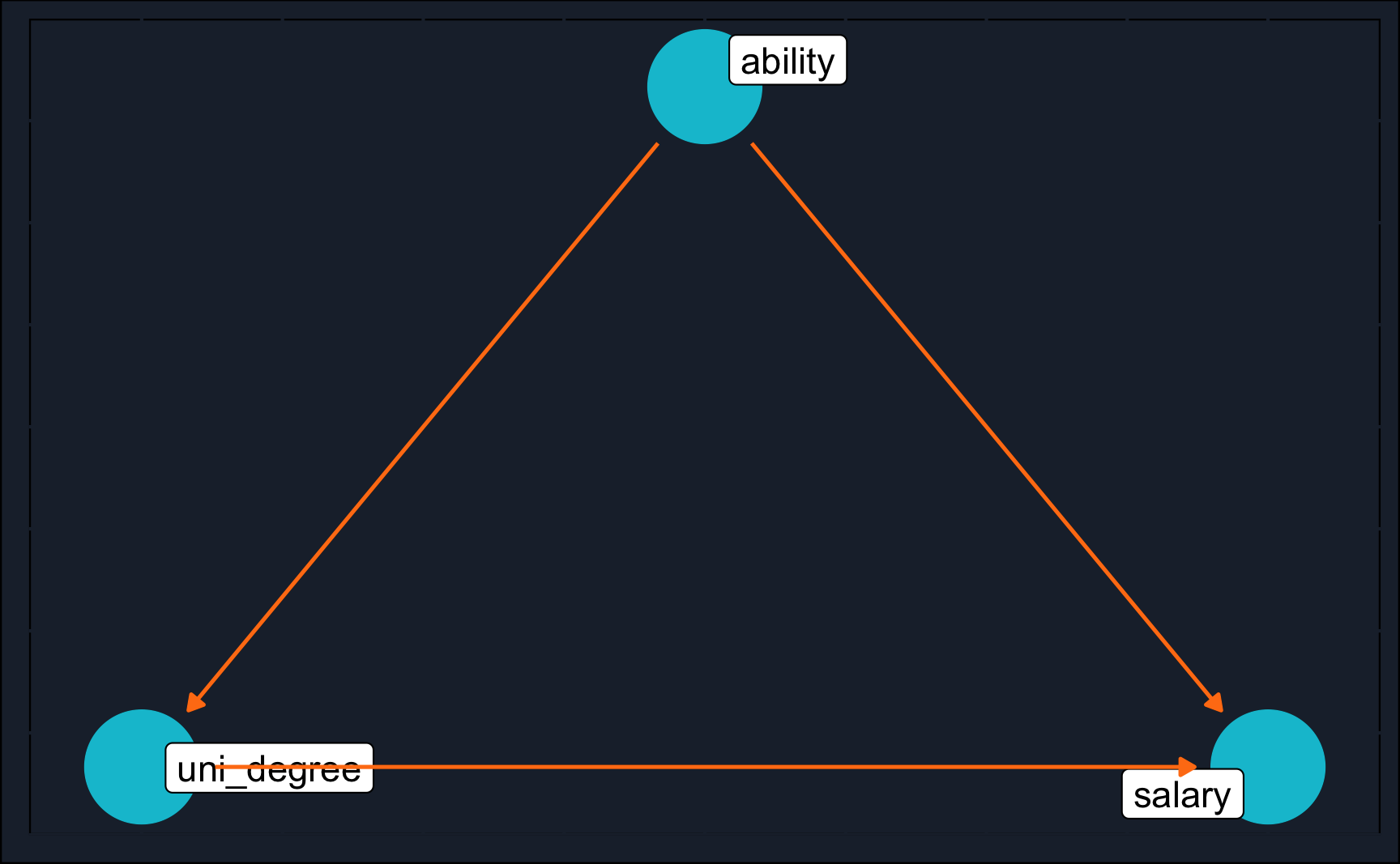
Option 3: Copy from dagitty.net to build graph in R
# Define DAG
schooling_dag_2 <- 'dag {
ability [pos="0.5, 0.4"]
salary [outcome,pos="0.8, 0"]
uni_degree [exposure,pos="0.2, 0"]
ability -> salary
ability -> uni_degree
uni_degree -> salary
}'
# Plot DAG
ggdag(schooling_dag_1, text = FALSE) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = NA) +
geom_dag_label_repel(aes(label = name), size = 4) +
geom_dag_edges(edge_color = ggthemr::swatch()[7])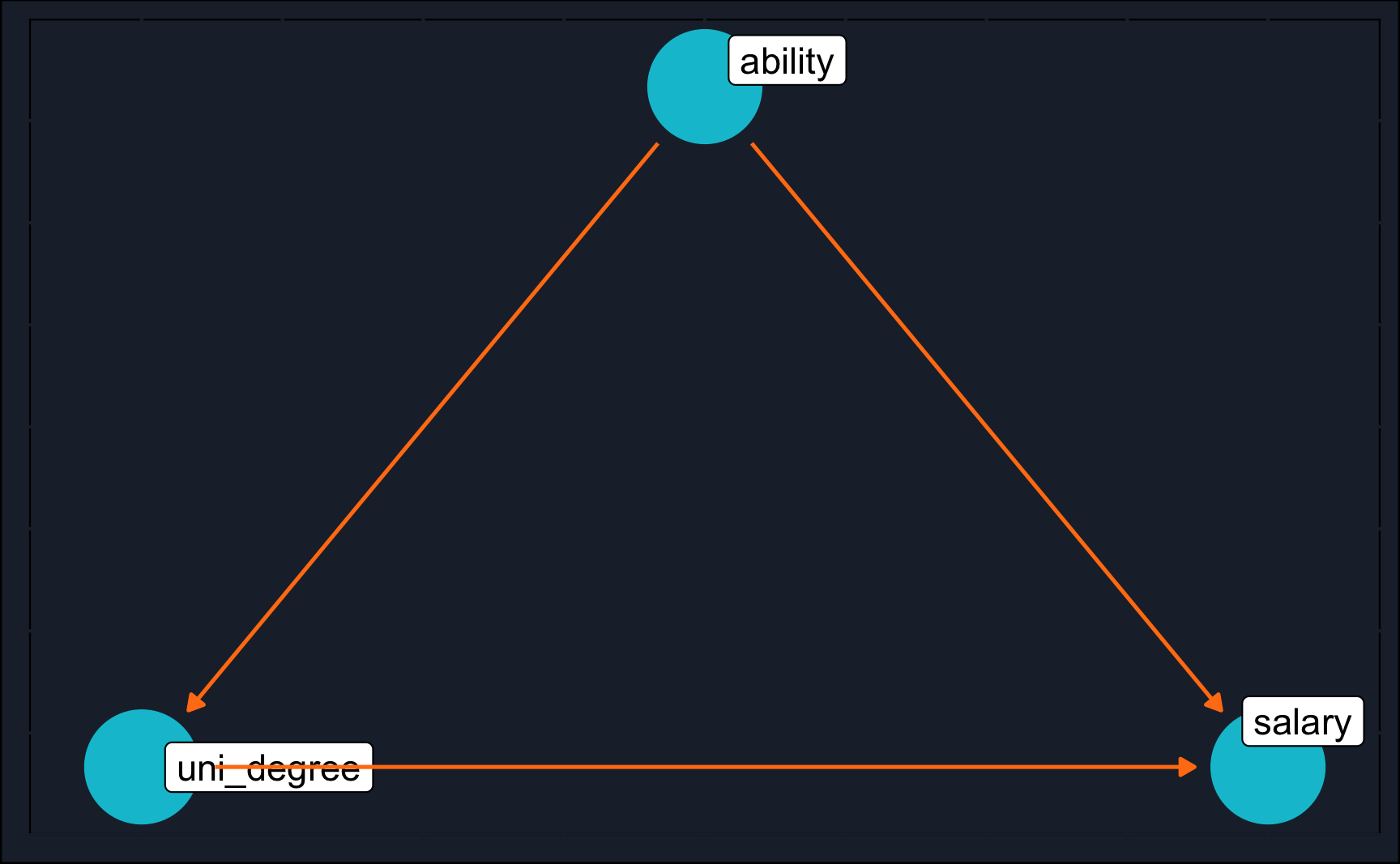
One great advantage of having our DAG coded into R or on DAGitty is the possibility to see what we have to adjust for. You can do that by running the command adjustmentSets() which returns all possible sets of variables that you can control for to retrieve a causal effect.
# Get adjustment sets. Because we already specified exposure and outcome when
# constructing the DAG, we do not need to do again. If they were not specified,
# you could do so by explicitly providing arguments ("exposure", "outcome")
adjustmentSets(schooling_dag_2){ ability }Most of the time, DAGs are more complex than the example above. Even in that example, there are many more variables that could be included, like social environment, gender etc. But although in practice DAGs are more complex, they can be disassembled in building blocks that are easier to analyze.
Effectively, there are only three different types of association we need to focus on:
Chain: \(X \rightarrow Z \rightarrow Y\)
Confounder: \(X \leftarrow Z \rightarrow Y\)
Collider: \(X \rightarrow Z \leftarrow Y\)
Knowing their characteristics and idiosyncrasies allows us to identify valid strategies to estimate causal effects. Then, you know which variables you have to include in your analysis and which ones you have to leave out. Because in case you include or exclude the wrong variables, you will end up with a biased results and you are not able to interpret your estimate causally.
It is important to understand (conditional) (in-)dependencies between, and with particular focus on conditional independence. An important concept you learned in the lecture is d-separation:
One element is a chain of random variables where the causal effect flows in one direction.
# Specify chain structure
chain <- dagify(
Y ~ Z,
Z ~ X,
coords = list(x = c(Y = 3, Z = 2, X = 1),
y = c(Y = 0, Z = 0, X = 0))
)
# Plot DAG
ggdag(chain) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = "white") +
geom_dag_edges(edge_color = ggthemr::swatch()[7])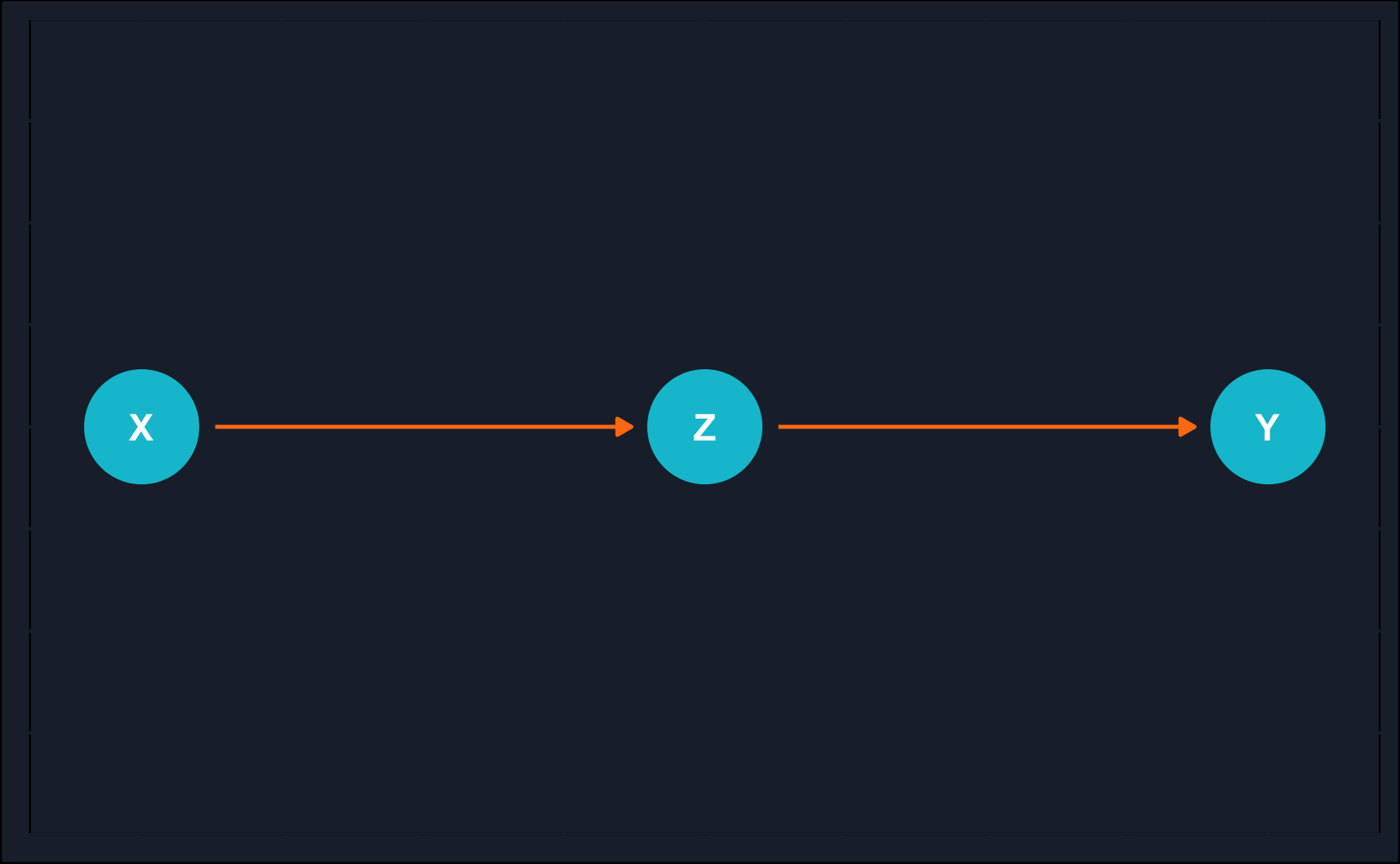
Consider the following variables:
This mechanism is also sometimes called mediation, because \(Z\) mediates the effect of \(X\) on \(Y\).
Question: Describe the dependencies in the DAG above.
Rule: Two variables, \(X\) and \(Y\), are conditionally independent given \(Z\), if there is only one unidirectional path between \(X\) and \(Y\) and \(Z\) is any set of variables that intercepts that path.
We can also check using the function dseperated(). It returns TRUE when two nodes are d-separated, which means that they are independent of each other. You need to provide \(X\) and \(Y\), which are the focal nodes and \(Z\), your set that you condition on.
# Check d-separation between X and Y
dseparated(chain, X = "X", Y = "Y", Z = c())[1] FALSE# Check d-separation between X and Y conditional on Z
dseparated(chain, X = "X", Y = "Y", Z = c("Z"))[1] TRUEAnother mechanism is the fork, also called common cause.
# Fork
fork <- dagify(
X ~ Z,
Y ~ Z,
coords = list(x = c(Y = 3, Z = 2, X = 1),
y = c(Y = 0, Z = 1, X = 0))
)
# Plot DAG
ggdag(fork) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = "white") +
geom_dag_edges(edge_color = ggthemr::swatch()[7])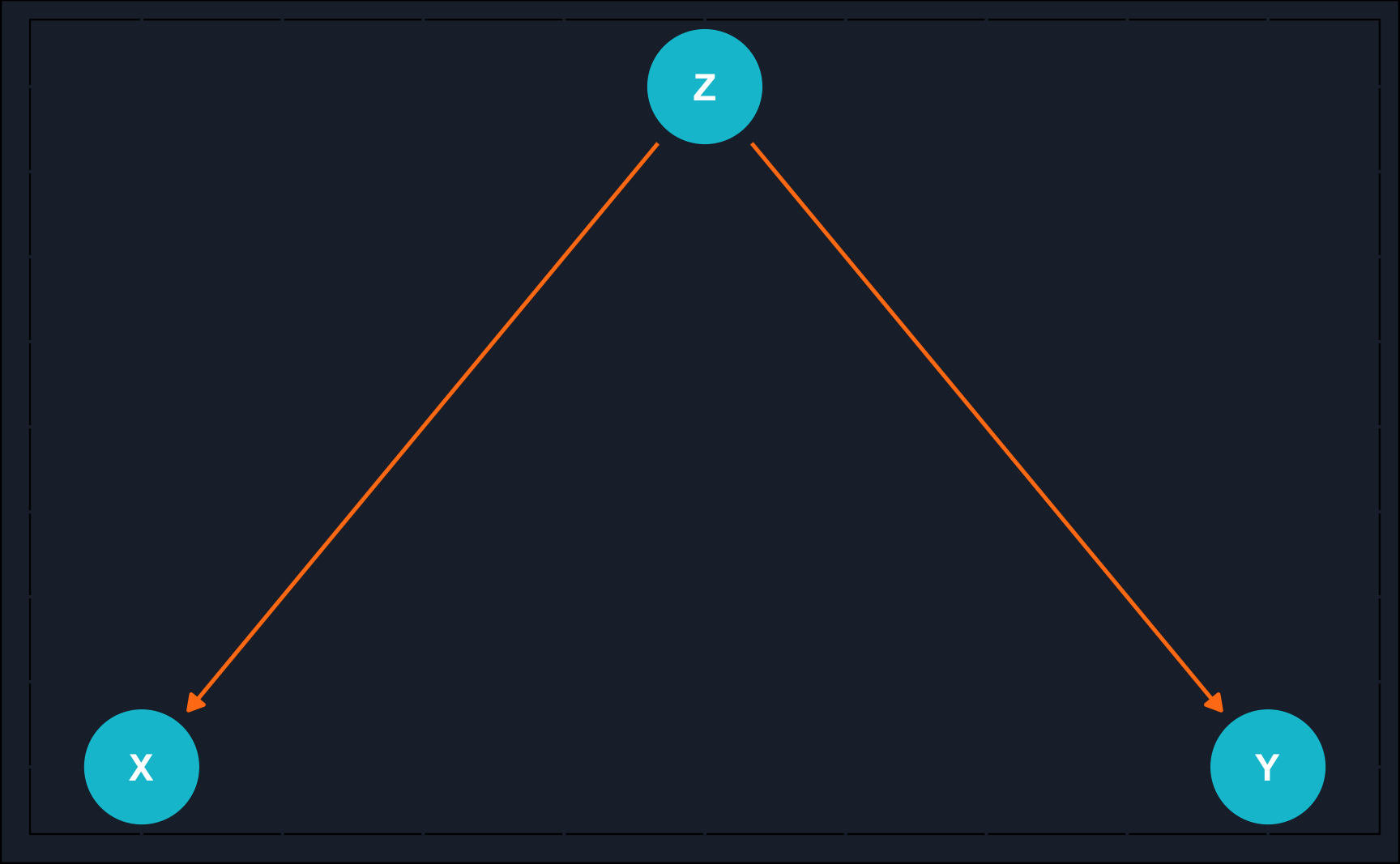
The reason it is called common cause is that, as depicted above, both \(X\) and \(Y\) are caused by \(Z\).
To illustrate it, consider the following scenario: \(Z\) represents the temperature in a particular town and \(X\) and \(Y\) represent ice cream sales and number of crimes in that same town, respectively.
Then, you could hypothesize that with increasing temperature people start to eat and buy more ice cream and also more crimes will happen as more people are outside which presents a greater opportunity for crime. Therefore ice cream sales and number of crimes tend to behave similarly in terms of direction and magnitude, they correlate.
However, there is no reason to assume there is a causal relationship between ice cream sales and the number of crimes.
Question: Describe the dependencies in the DAG above.
Rule: If variable \(Z\) is a common cause of variables \(X\) and \(Y\), and there is only one path between \(X\) and \(Y\), then \(X\) and \(Y\)are independent conditional on X.
Again, we also check using R.
# Check d-separation between X and Y conditional on Z
dseparated(fork, X = "X", Y = "Y", Z = c("Z"))[1] TRUE# Check d-separation between X and Y
dseparated(fork, X = "X", Y = "Y", Z = c())[1] FALSEThe last mechanism is the collision, which is also called common effect.
# Collider
collider <- dagify(
Z ~ X,
Z ~ Y,
coords = list(x = c(Y = 3, Z = 2, X = 1),
y = c(Y = 1, Z = 0, X = 1))
)
# Plot DAG
ggdag(collider) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = "white") +
geom_dag_edges(edge_color = ggthemr::swatch()[7])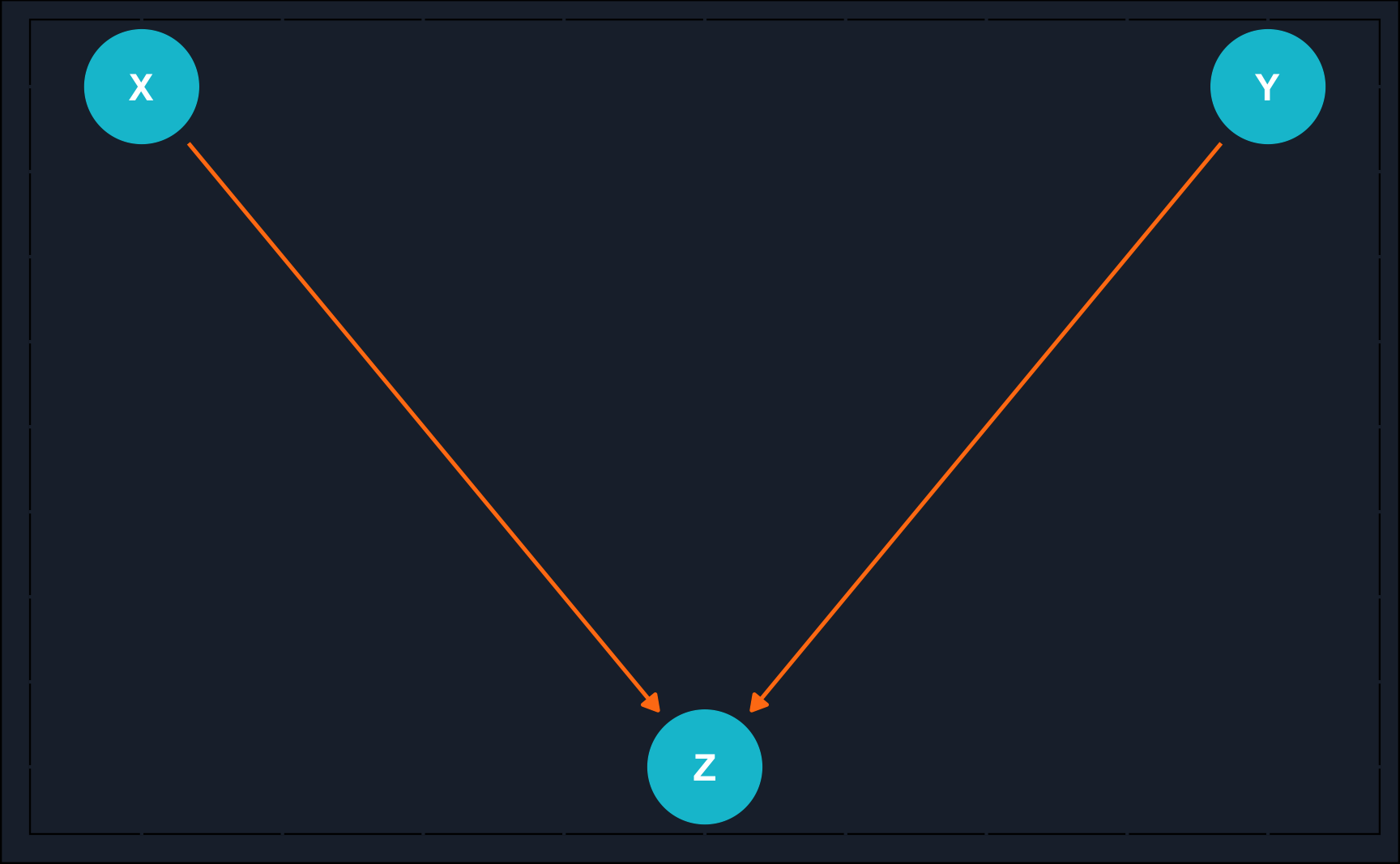
It is the reflection of the fork and both \(X\) and \(Y\) have a common effect on the collision node \(Z\).
This time, as we are already used to it, we will start to list the dependencies and then use an example for illustration:
A popular way to illustrate the common effect, especially the last dependency, is to take an example that is related to Berkson’s paradox.
For example, imagine the variables to be:
First of all, in the general population, there is no correlation between programming skills and social skills (3rd dependency). Second, having either programming or social skills will land you a job a a tech company (1st and 2nd dependency).
But what about the last dependency? Why are programming and social skills suddenly correlated when conditioned on e.g. being hired by a tech company? That is because when you know someone works for a tech company and has no programming skill, the likelihood that he/she has social skills increases because otherwise he/she would have likely not be hired. Vice versa, if you know someone has been hired and has no social skills, he/she is probably a talented programmer.
Rule: If a variable \(Z\) is the collision node between two variables \(X\) and \(Y\), and there is only one path between \(X\) and \(Y\), then \(X\) and \(Y\) are unconditionally independent but are dependent conditional on \(Z\) (and any descendants of \(Z\)).
Same procedure as above, checking using R.
# Check d-separation between X and Y
dseparated(collider, X = "X", Y = "Y", Z = c())[1] TRUE# Check d-separation between X and Y conditional on Z
dseparated(collider, X = "X", Y = "Y", Z = c("Z"))[1] FALSE# create DAG from dagitty
dag_model <- 'dag {
bb="0,0,1,1"
X [exposure,pos="0.075,0.4"]
Y [outcome,pos="0.4,0.4"]
M [pos="0.2,0.4"]
Z1 [pos="0.2,0.2"]
Z2 [pos="0.3,0.5"]
Z3 [pos="0.2,0.6"]
Z4 [pos="0.4,0.6"]
X -> M
M -> Y
X -> Z3
Z1 -> X
Z1 -> Y
Z2 -> Y
Z2 -> Z3
Z3 -> Z4
}
'
# draw DAG
ggdag_status(dag_model) +
guides(fill = "none", color = "none") + # Disable the legend
theme_dag_cds() + # custom theme, can be left out
geom_dag_edges(edge_color = ggthemr::swatch()[7])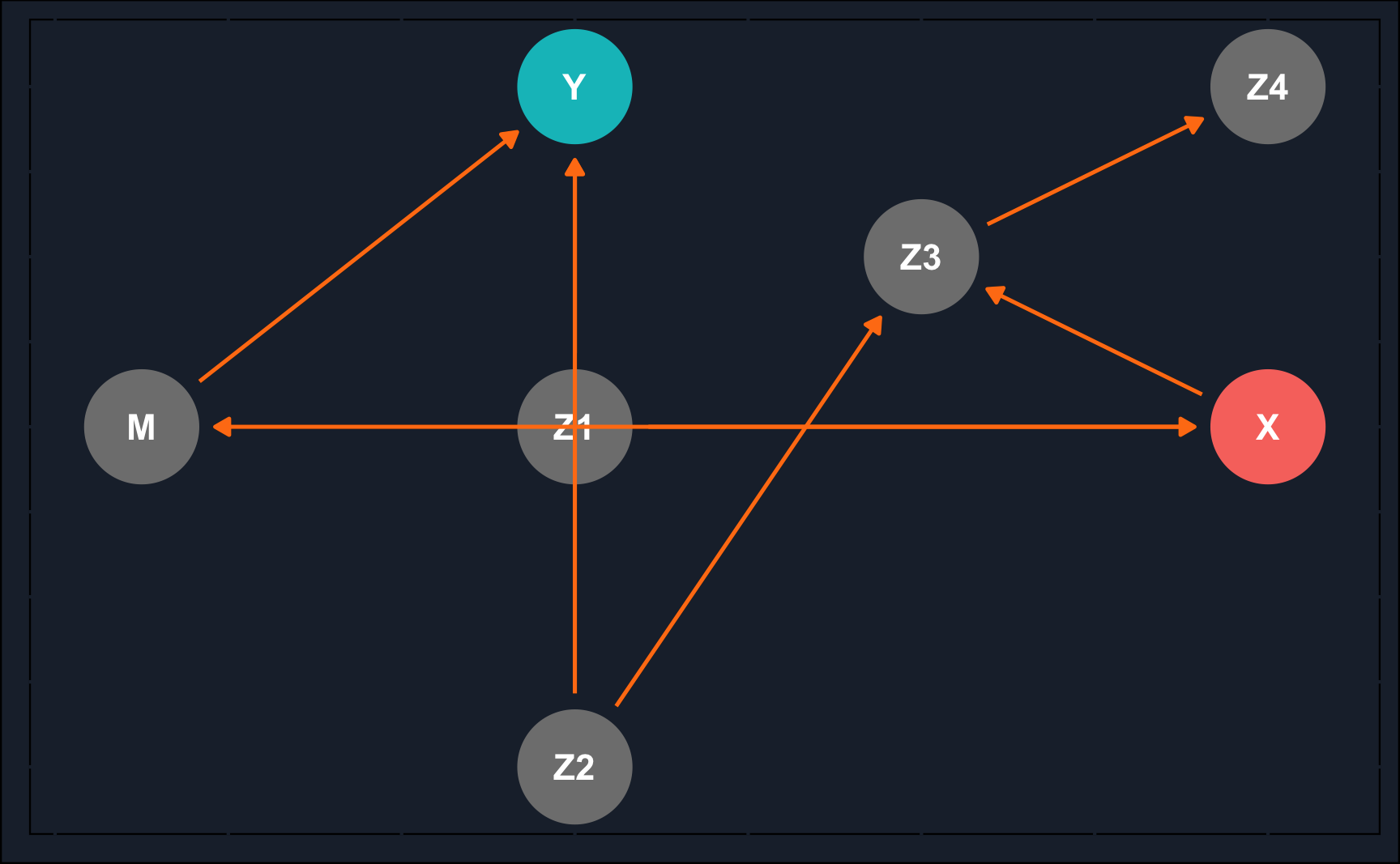
For each of the following scenarios, explain whether the nodes \(X\) and \(Y\) are d-separated.
dseparated(dag_model, X = "X", Y = "Y", Z = c())[1] FALSEdseparated(dag_model, X = "X", Y = "Y", Z = c("M", "Z1"))[1] TRUEdseparated(dag_model, X = "X", Y = "Y", Z = c("M", "Z3"))[1] FALSEdseparated(dag_model, X = "X", Y = "Y", Z = c("M", "Z1", "Z4"))[1] FALSEdseparated(dag_model, X = "X", Y = "Y", Z = c("M", "Z1", "Z2", "Z4"))[1] TRUE# RCT
rct <- dagify(
Y ~ X,
Y ~ Z,
coords = list(x = c(Y = 3, Z = 2, X = 1),
y = c(Y = 1, Z = 2, X = 1))
)
# Plot DAG
ggdag(rct) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = "white") +
geom_dag_edges(edge_color = ggthemr::swatch()[7])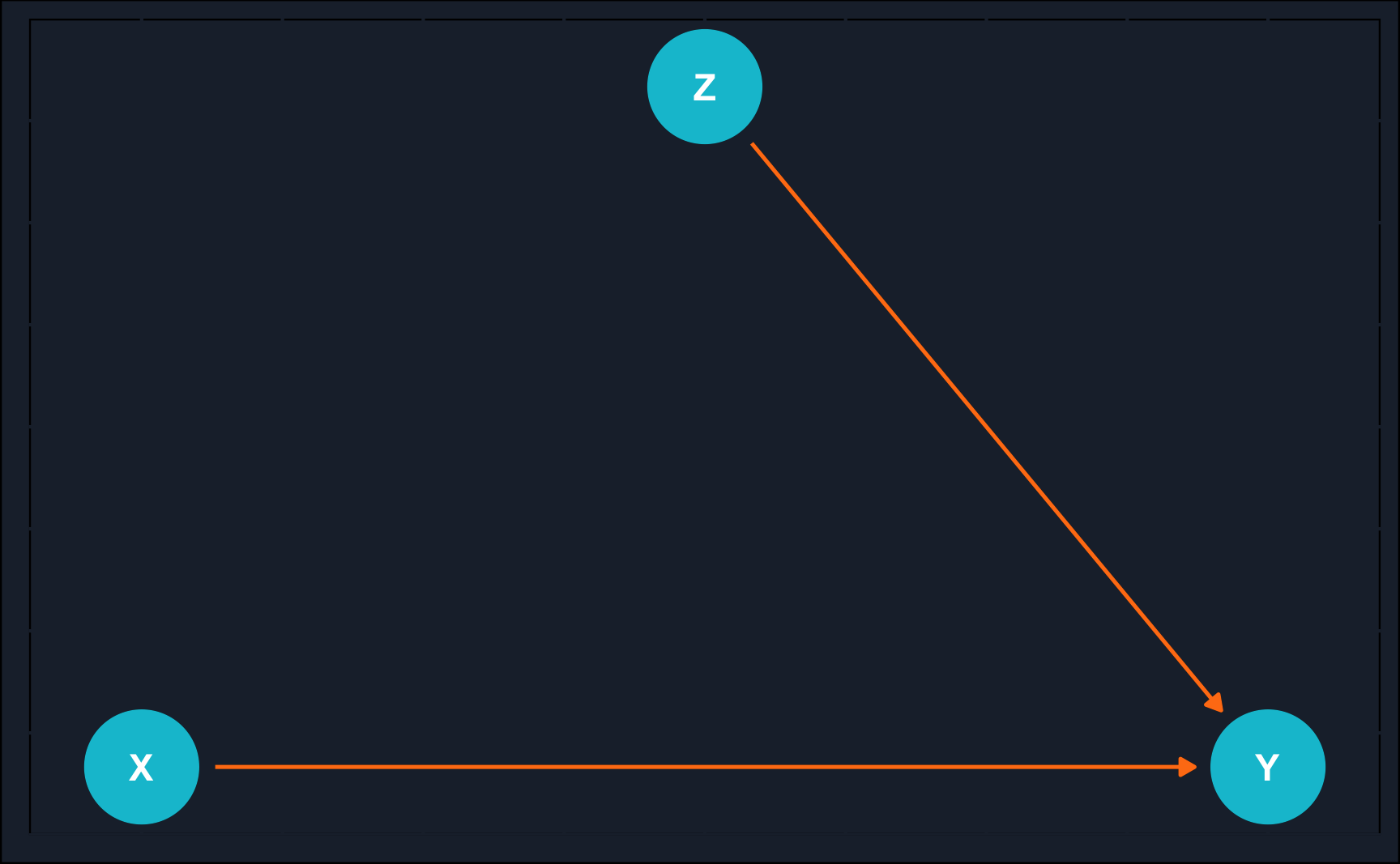
Consider this scenario: You aim to determine the effectiveness of hiring top consultants for your company and quantify this impact. You have access to a large company database containing profit data from both the previous and current years, along with information on whether companies have hired top consultants.
First, we are going to load the data (You’ll need to download the data first).
# A tibble: 1,000 × 4
company previous_profit consultant profit
<int> <dbl> <int> <dbl>
1 1 7.46 1 7.44
2 2 5.92 0 5.03
3 3 7.47 1 7.32
4 4 8.73 1 8.39
5 5 6.65 0 5.75
6 6 2.47 0 2.13
7 7 4.59 0 4.06
8 8 5.80 1 5.99
9 9 5.83 1 5.9
10 10 4.39 0 3.72
# ℹ 990 more rowsBy now, you have learned that the first step in causal inference - before estimating the treatment effect - is the identification and in this chapter you have learned a useful graphical tool: DAGs. Let’s draw the DAG that shows your understanding of the scenario and find out how we are able to recover the causal effect of hiring consultants on profits.
Let’s discuss each possible dependency:
# Construct DAG
profits_dag <- dagify(
consultant ~ previous_profit,
profit ~ previous_profit,
profit ~ consultant,
coords = list(x = c(consultant = 1, profit = 3, previous_profit = 2),
y = c(consultant = 1, profit = 1, previous_profit = 2))
)
# Plot DAG
ggdag(profits_dag, text = FALSE) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = NA) +
geom_dag_label_repel(aes(label = name), size = 4) +
geom_dag_edges(edge_color = ggthemr::swatch()[7])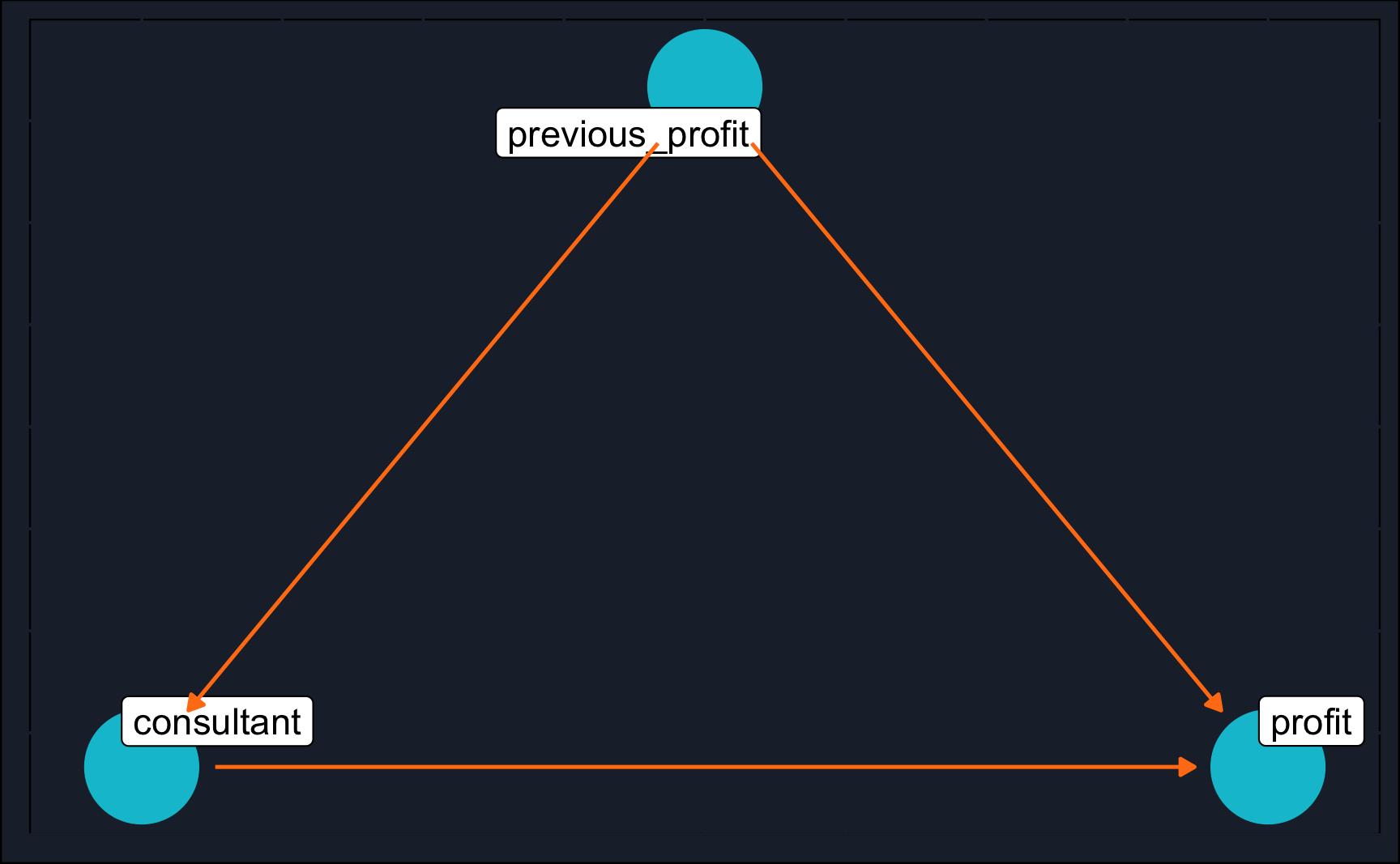
By now, you are probably already able to see it on a first glance because you know what a confounder is and how to adjust for it. But for the purpose of demonstration, let’s dagitty tell us what we need to adjust for.
# Adjustment set
adjustmentSets(profits_dag, exposure = "consultant", outcome = "profit"){ previous_profit }As expected, it is the backdoor adjustment which we need to perform in our estimation. We need to control for the previous profits because more previously profitable companies are more likely to hire top consultants and are more likely to make profits again.
In the lecture, you have learned the following formula to satisfy the backdoor criterion: condition on the values of your adjustment set and average over the joint distribution.
\[ P(Y|do(D)) = \sum\nolimits_W P(Y|D=d, W=w) P(W=w) \] We slightly rewrite the so-called adjustment formula to highlight what we need to do in the estimation step.
\[ \begin{align} ATE &= E_W[E(Y|D=1) - E(Y|D=0)] \\ ATE &= \sum_{w \in W} [E(Y|D=1, W=w) - E(Y|D=0, W=w)] P(W=w) \\ &= \sum_{w \in W} [E(Y|D=1, W=w)P(W=w) - E(Y|D=0, W=w)P(W=w)] \end{align} \] When dealing with only a few values of \(W\), you condition by examining each group \(w \in W\), comparing treated and untreated observations within each group, and then averaging the outcomes, with the group sizes serving as weights. Remember, you assume that within the groups the treatment must look as if it was as good as randomly assigned.
However, when we look at our adjustment set, which is the previous profit of a company, we see that there are not only a couple of values, but theoretically, previous profits could take any real number.
summary() provides a concise summary of the statistical properties of data objects such as data frames, vectors or even models.
# Statistical summary of column of previous profits
summary(profits$previous_profit) Min. 1st Qu. Median Mean 3rd Qu. Max.
-1.0 4.0 5.6 5.6 7.1 13.5 In the following weeks, we will learn sophisticated methods to deal with continuous confounders, but today, we refer to a simpler method. We assign each company to a group determined by the value of previous profits. The function ntile() does the job: it splits the data into \(n\) equally sized groups ordered by size.
In R, pipes |> are used to chain together multiple operations in a readable and concise manner. The |> operator (shortcut: cmd/ctrl + shift + m) passes the output of one function as the first argument to the next function. This makes code easier to understand by avoiding nested function calls and enhancing code readability.
In R, group_by() is used to group data by one or more variables, summarise() computes summary statistics within each group, and ungroup() removes grouping structure. These functions are commonly used together in data manipulation workflows and belong to the tidyverse (dplyr). n() is a function specifically for such grouping operations. It does not take any arguments and counts the number of rows in each group.
# Split group into n equally sized groups
profits$group <- ntile(profits$previous_profit, n = 4)
# Compute mean value and number of observations by group
profits_by_group <- profits |>
# What columns to group by
group_by(group, consultant) |>
# What columns to use for aggregation and what kind of aggregations
summarise(
# Average profit by group
mean_profit = mean(profit),
# Number of observations by group
nobs = n()
) |>
# Remove grouping structure
ungroup()
# Show table
print(profits_by_group)# A tibble: 8 × 4
group consultant mean_profit nobs
<int> <int> <dbl> <int>
1 1 0 2.45 181
2 1 1 3.44 69
3 2 0 4.05 189
4 2 1 5.02 61
5 3 0 5.31 67
6 3 1 6.33 183
7 4 0 7.03 58
8 4 1 8.28 192In R, pivot_wider() is a function included in the tidyverse (tidyr) used to convert data from long to wide format. It reshapes data by spreading values from a column into multiple columns, with each unique value in that column becoming a new column. This is particularly useful for creating summary tables or reshaping data for analysis and visualization.
mutate() in R’s dplyr (incl. in tidyverse) adds new columns to a data frame, allowing you to transform or calculate values based on existing columns.
# Convert to wide format to compute effect
te_by_group <- profits_by_group |>
# Convert column values of consultant to headers and take values from
# mean_profit
pivot_wider(
# For each group, we want one row
id_cols = "group",
# Values of consultants to headers
names_from = "consultant",
# Take values from 'mean_profit'
values_from = "mean_profit",
# Change names of headers for better readability
names_prefix = "consultant_"
) |>
# Compute group treatment effect by subtracting mean of untreated units from
# mean of treated units
mutate(te = consultant_1 - consultant_0)
# Show table
print(te_by_group)# A tibble: 4 × 4
group consultant_0 consultant_1 te
<int> <dbl> <dbl> <dbl>
1 1 2.45 3.44 0.993
2 2 4.05 5.02 0.964
3 3 5.31 6.33 1.01
4 4 7.03 8.28 1.24 Because all groups have the same size the weighted average is equal to the average and we can simply take the average to obtain the ATE:
# Taking the average of the treatment effect column. Same as weighted mean,
# because group sizes are identical.
mean(te_by_group$te)[1] 1.1# With weighted mean
weighted.mean(te_by_group$te, c(250, 250, 250, 250))[1] 1.1One assumption that needs to be fulfilled for the treatment effect to be valid is the positivity assumption we discussed in the last week. Let’s recall it (slightly rewritten to match the notation of our example):
Question: Is the positivity assumption satisfied?
Yes, because in each group, we have observations from both groups. Take a look at the column nobs in the table profits_by_group.
For the sake of demonstration, let’s see what would have happened, had we not adjusted for the previous profits:
# Naive estimate
y1 <- mean(profits[profits$consultant == 1, ]$profit)
y0 <- mean(profits[profits$consultant == 0, ]$profit)
y1 - y0[1] 2.5Warning: The `scale_name` argument of `discrete_scale()` is deprecated as of ggplot2 3.5.0.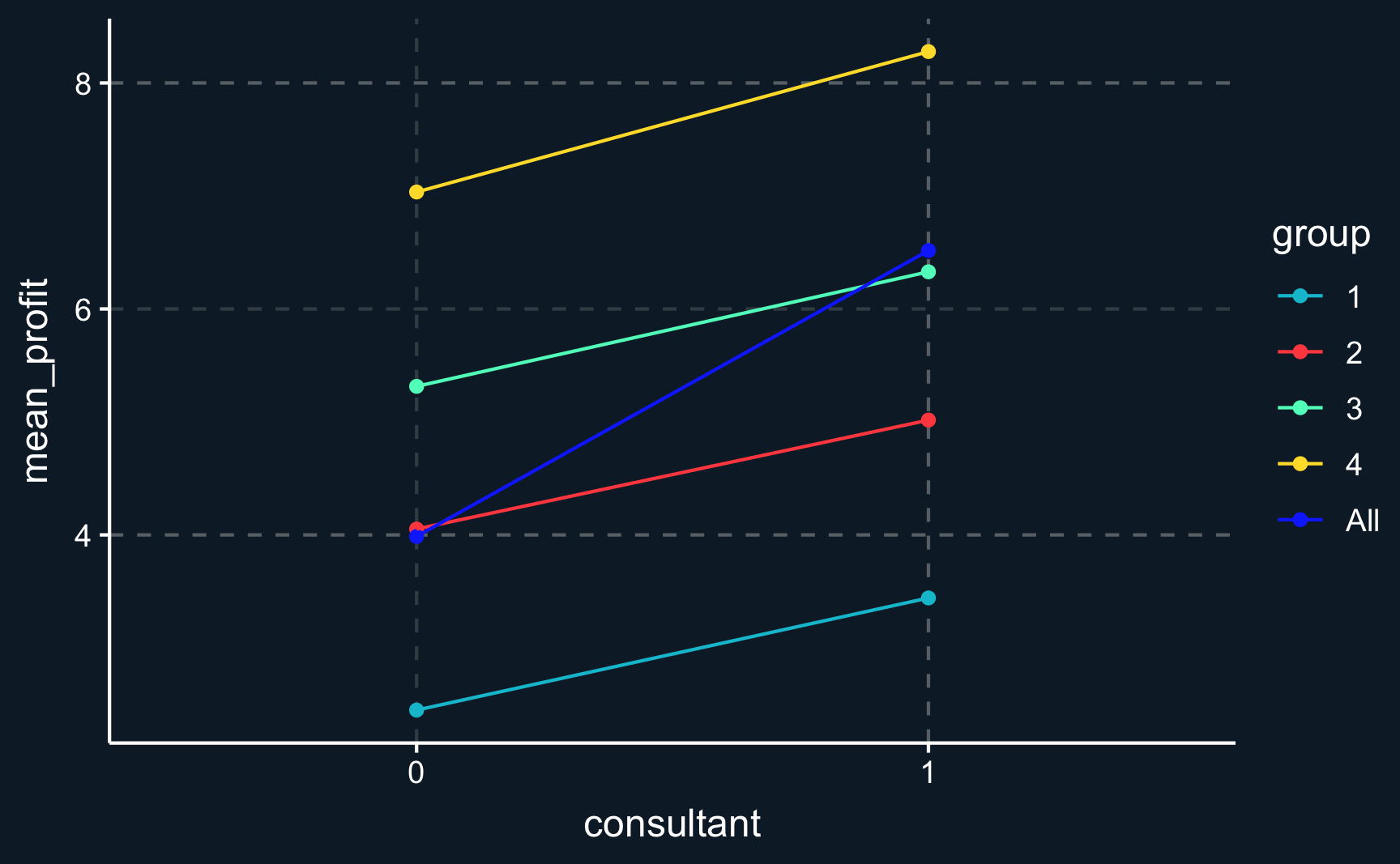
Imagine you’re at a software company, introducing a new feature and keen to gauge its impact. To ensure unbiased results, you conduct a randomized rollout: 10% of customers receive the new feature randomly, while the rest do not. Your aim is to assess if this feature enhances customer satisfaction, indirectly measured through Net Promoter Score (NPS). You distribute surveys to both the treated (with the new feature) and control groups, asking if they would recommend your product. Upon analysis, you observe higher NPS scores among customers with the new feature. But can you attribute this difference solely to the feature? To delve into this, start with a graph illustrating this scenario.
Identification
Graphically modeling the described scenario, you’ll end up with:
rollout_dag <- 'dag {
bb="0,0,1,1"
"Customer satisfaction" [pos="0, 1"]
"New feature" [exposure,pos="0, 0"]
NPS [outcome,pos="1,1"]
Response [adjusted,pos=".8, 0"]
"Customer satisfaction" -> NPS
"Customer satisfaction" -> Response
"New feature" -> "Customer satisfaction"
"New feature" -> Response
Response -> NPS
}'
ggdag(rollout_dag, text = FALSE) +
theme_dag_cds() + # custom theme, can be left out
geom_dag_point(color = ggthemr::swatch()[2]) +
geom_dag_text(color = NA) +
geom_dag_label_repel(aes(label = name), size = 4) +
geom_dag_edges(edge_color = ggthemr::swatch()[7])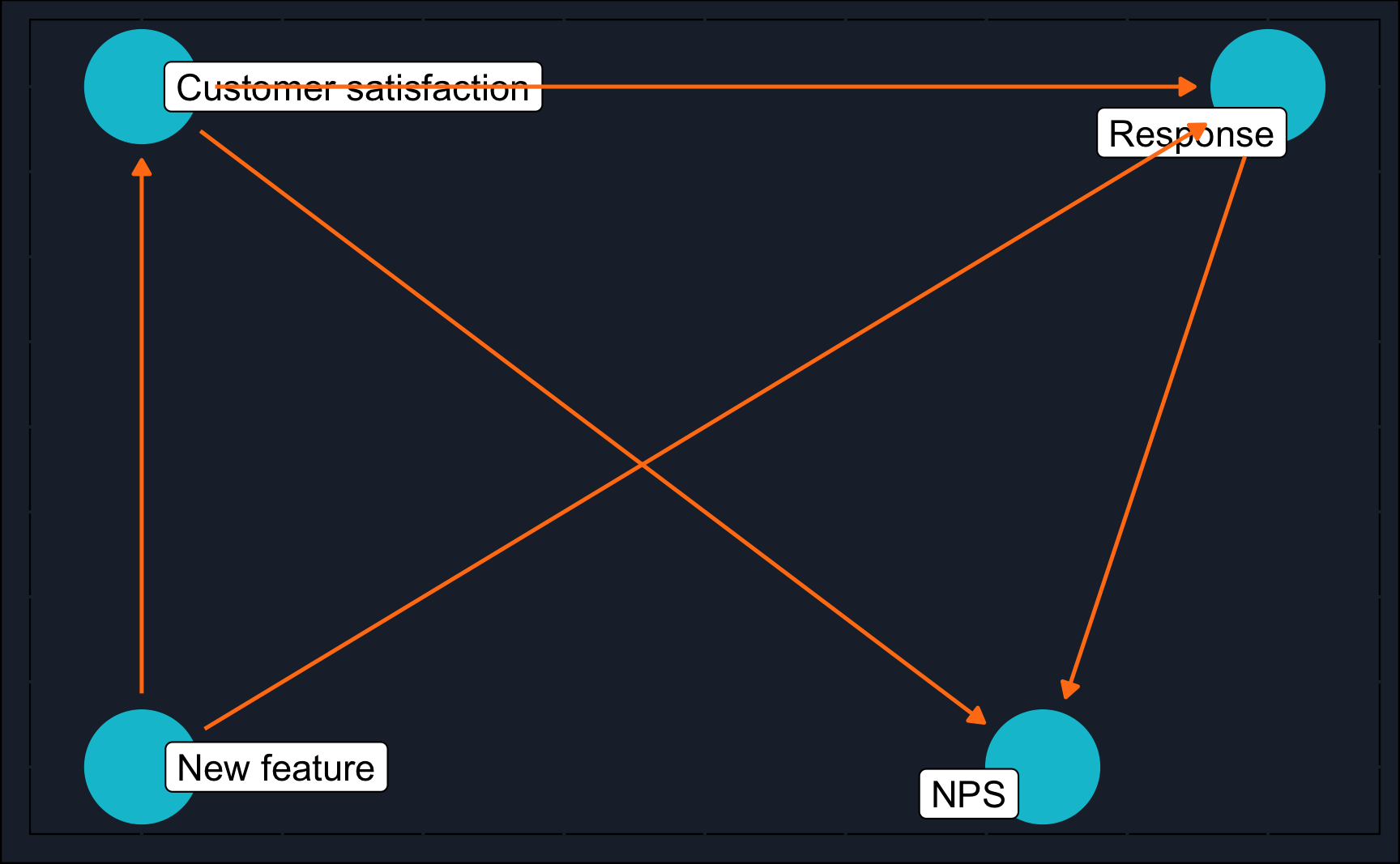
Argue, what needs to be adjusted for to compute the effect of the new feature on the net promoter score (NPS).
Accept the Week 2 - Assignment and follow the same steps as last week and as described in the organization chapter.
Solve the following assignment:
Load the data health_program.rds and first take a look at the data.
Imagine the following scenario: you are manager of a company and want to reduce the number of sick days in your company by implementing a health program that employees are free to participate in. By learning about how to improve their health, you expect your employees to call in sick less frequently. Some time after implementing the health_program, you’ll observe the sick_days for each employee and want to estimate the average treatment effect. You know that because of the voluntary basis of participating in the program, other variables might confound your estimate if you compute a naive estimate of the average treatment effect. So you might apply what you have learned in the last weeks about confounding, adjusting etc.
First, load the data health_program.rds and first take a look at the data.For the purpose of this task, we assume that all variables we need for a valid estimation are included in the data.
Take a look at all variables that are included in the data. List all pairs of variables and argue whether there might be a dependency and what direction you assume for that relationship if present.
Map your explanations from the previous task into a DAG using dagitty and ggdag. Define exposure and treatment for that DAG.
Based on your DAG, what variables do you need to control for? Explain in a short paragraph.
Estimate the average treatment effect based on your previous explanations. (Hint: id_cols in pivot_wider can take more than one value by providing a vector id_cols = c("var1", "var2")).
Explain, whether the positivity assumption is satisfied.
Estimate the average treatment effect without conditioning on any variables and compare to the treatment effect computed in 4. Explain the difference.
In this chapter, we already used some functions from the tidyverse. Functions from the tidyverse, are often preferred over base R functions for several reasons:
Readability and Expressiveness: Tidyverse functions use a consistent and expressive syntax, making code easier to read and write. This can enhance collaboration and reduce errors.
Piping: Tidyverse functions work well with the |> pipe operator, allowing for a more fluid and readable data manipulation workflow.
Tidy Data Principles: Tidyverse functions are designed around the principles of tidy data, which promotes a standardized way of organizing data that facilitates analysis and visualization.
For an overview of base R vs tidyverse functions, you can read here.