Last week, we discussed the significant advantage of employing a randomized treatment assignment: it allowed straightforward comparisons of group averages or the application of univariate linear regressions (i.e., with only one variable on the right-hand side), thereby easing statistical inference.
However, what if the treatment isn’t randomized? We’ve discovered that when developing our identification strategy, we must consider confounding variables and implement measures to control for them. How do we do this? In this chapter, you’ll delve into (1) a regression-based approach, (2) a matching-based approach, and (3) a weighting-based approach to address this challenge.
Tip
There are many terms used to account for a confounder which are used interchangeably. Among other, depending on the perspective, you could “block a backdoor path”, “condition on a confounder”, “adjust for the confounder”, or “control for the confounder”.
Regression adjustment
In this scenario, similar to the example from the first week, you’re the owner of an online marketplace enterprise aiming to assist businesses on your platform with strategic pricing guidance. However, please recall that these businesses operate anonymously and independently determine their pricing, rendering the treatment non-randomized. Once more, our focus remains on a particular category of similar products: light jackets. While in the initial week, we denoted the treatment as being on sale, this time, we adopt a more precise approach, utilizing price — a continuous variable - as the treatment.
Downloading, reading and printing the data, we see that each row represents an observation detailing the daily sales of a particular business with additional information such as the weekday and the product rating. In total, you collected 10’000 observations.
Reading and printing the data, it’s evident that each of the 10’000 rows represents an observation detailing the daily sales of a specific business, accompanied by supplementary information like the weekday and product rating.
With the regression-based approach, we employ a multivariate linear regression that incorporates confounding variables. In essence, we estimates the treatment effect conditionally on covariates.
Following the Frisch–Waugh–Lovell theorem, you can decompose your regression into a three-stage process and obtain identical estimates. The idea behind this is to initially eliminate all variation in \(D\) and \(Y\) that can be explained by the covariates \(X\). Subsequently, you account for the remaining variation in \(Y\) using the remaining variation in \(D\).
Denoising: run a regression of the form \(Y_i = \beta_{Y0} + \mathbf{\beta_{Y \sim X}' X_i} + \epsilon_{Y_i \sim X_i}\) and extract the estimated residuals \(\hat\epsilon_{Y_i \sim X_i}\).
Debiasing: run a regression of the form \(D_i = \beta_{D0} + \mathbf{\beta_{D \sim X}' X_i} + \epsilon_{D_i \sim X_i}\) and extract the estimated residuals \(\hat\epsilon_{D_i \sim X_i}\).
Residual regression: run a residual-on-residual regression of the form \(\hat\epsilon_{Y_i \sim X_i} = \beta_D \hat\epsilon_{D_i \sim X_i} + \epsilon_i\) (no constant).
Q2. Use the three-step procedure as described above to obtain the estimate. Check that they are identical to the estimates obtained with lm().
Tip
Hints:
When you run a model with lm(), residuals are automatically computed. You can access them by model_name$residuals. Residuals are the difference between the actual value and the value predicted by the model. By construction of the ordinary least square regression, residuals are zero on average.
To run a model without a constant/intercept, use y ~ 0 + ....
Call:
lm(formula = Y_hat ~ 0 + D_hat)
Residuals:
Min 1Q Median 3Q Max
-53.40 -7.41 0.51 8.22 39.36
Coefficients:
Estimate Std. Error t value Pr(>|t|)
D_hat -2.690 0.121 -22.1 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 12 on 9999 degrees of freedom
Multiple R-squared: 0.0468, Adjusted R-squared: 0.0467
F-statistic: 491 on 1 and 9999 DF, p-value: <2e-16
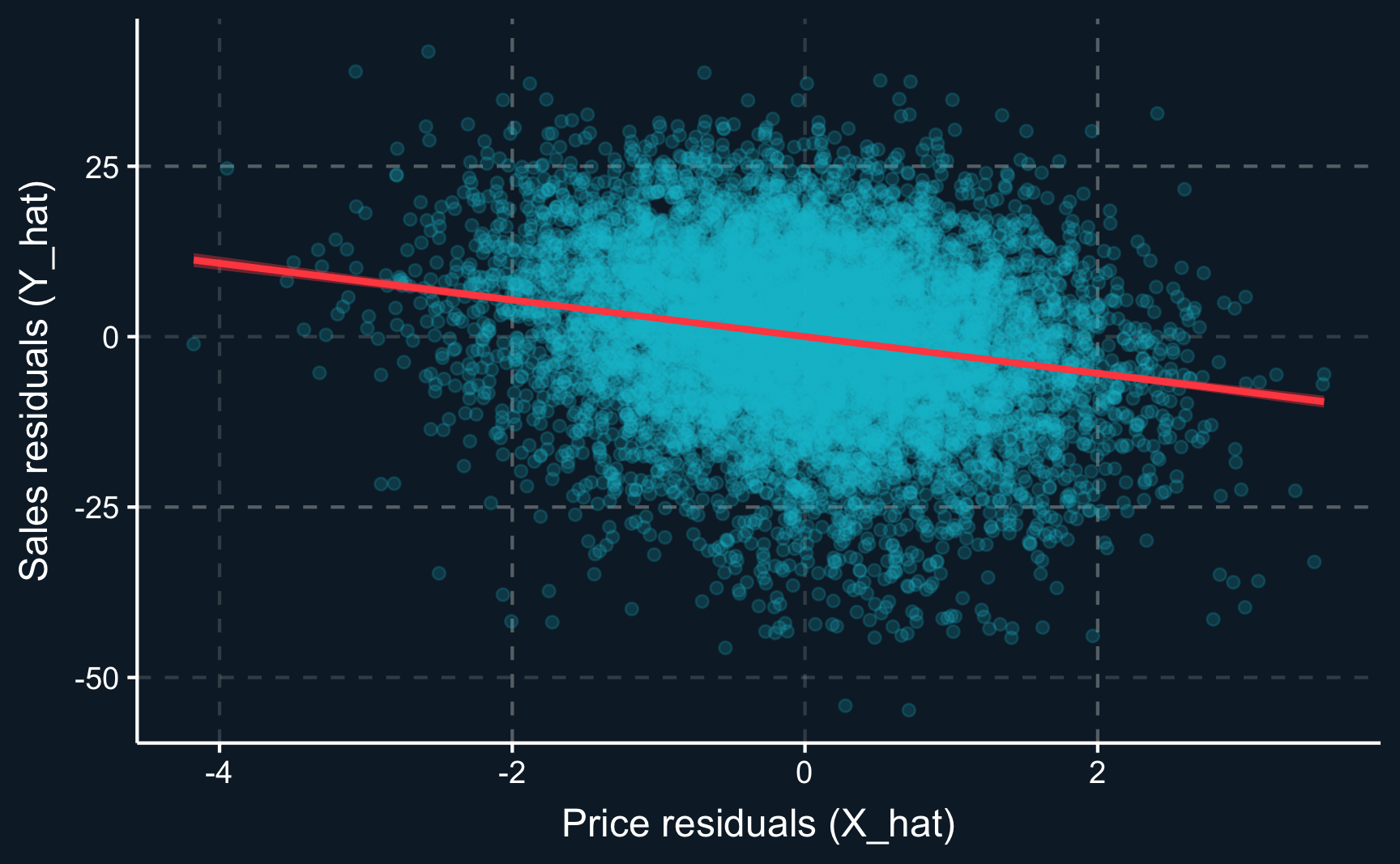
Let’s visualize what we have done in the steps before and what the FWL theorem makes so intuitive. With the regression-based approach, we account for the confounders by remove variance in both \(D\) and \(Y\) due to \(X\) and then, we perform a “clean” residual regression.
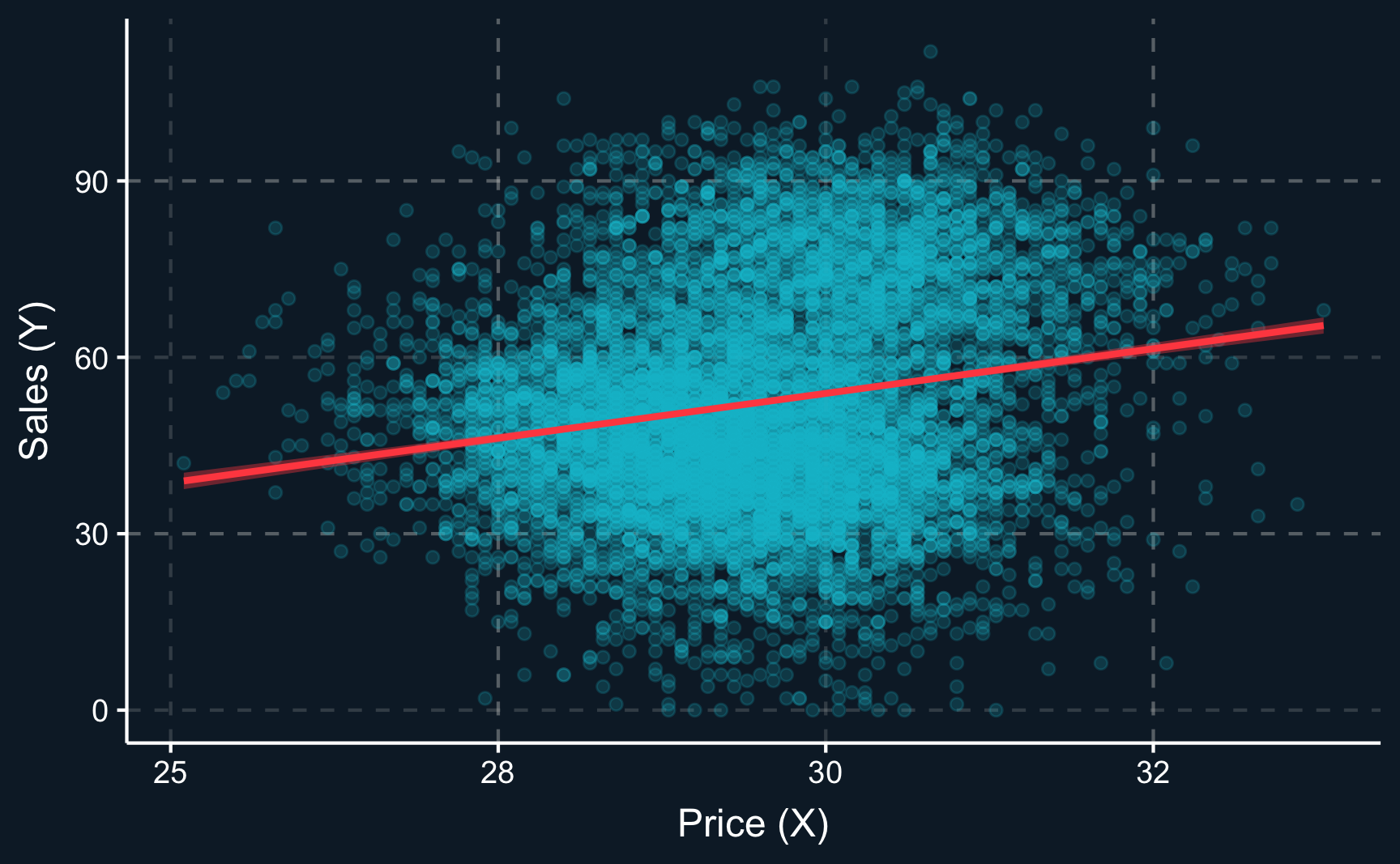
When we would simply run a normal regression without any accounting for the confounder, we would obtain what is depicted here. There does not appear to be a relationship between price and sales.
However, when we do account for the confounders and regress the residual \(\hat{Y}\) on the residual \(\hat{D}\), we obtain what is expected: a negative correlation. Higher prices lead to fewer sales.
Code
# Add residuals to data frameprices<-prices|>mutate(sales_hat =Y_hat, price_hat =D_hat)# Plotggplot(prices, aes(y =sales_hat, x =price_hat))+geom_point(alpha =.2)+geom_smooth(method='lm')+labs(x ="Price residuals (X_hat)", y ="Sales residuals (Y_hat)")
Q3. Compute the estimate that describes what is shown in the first plot.
Code
# Naive estimatemod_naive<-lm(sales~price, data =prices)summary(mod_naive)
Call:
lm(formula = sales ~ price, data = prices)
Residuals:
Min 1Q Median 3Q Max
-57.81 -13.04 -1.43 12.61 56.21
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -37.275 4.627 -8.06 8.7e-16 ***
price 3.038 0.157 19.37 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 18 on 9998 degrees of freedom
Multiple R-squared: 0.0362, Adjusted R-squared: 0.0361
F-statistic: 375 on 1 and 9998 DF, p-value: <2e-16
Matching
Imagine another situation. You are operating an online shop, and a year ago, introduced a plus membership aimed at binding customers and driving revenue growth. The plus memberships comes at a small cost for the customers, which is why not all of the customers subscribed. Now you want to examine whether binding customers by this membership program in fact increases your sales with subscribed customers. However, it’s essential to consider potential confounding variables such as age, gender, or previous average purchase amounts.
Each row in your dataset corresponds to a different customer, with accompanying demographic details, their average purchase sum before the introduction of the plus membership, their current average purchase, and an indication of their participation in the plus membership program.
# Read data and showmembership<-readRDS("membership.rds")print(membership)
Now, we’ll delve into the matching-based approach, an alternative to regression for addressing backdoor bias. The concept is to find and match treated and non-treated units with similar or identical covariate values. This method aims to replicate the conditions of a randomized experiment, assuming we have observed all confounding variables. Matching encompasses various techniques aimed at equalizing or balancing the distribution of covariates between the treatment and control groups. Essentially, the objective is to compare “apples to apples” and ensure that treatment and control groups are as similar as possible, except for the treatment variable.
In R, there are several packages available to facilitate matching-based methods, one of which is the MatchIt package. You’ll need to install this package first and then load it.
By enforcing treatment and control group to have little variation in the matching variables, we close the backdoors. When the backdoor variable does not vary or varies only very little, it cannot induce changes in treatment and outcome. So, when we suppress this variation in the backdoor variable, we can interpret the effect from treatment to outcome as causal.
One-vs-one matching
The procedure consists of two steps, matching and estimation. Let’s start with a one-vs-one matching. Because, as our estimand, we specify \(ATT\), the average treatment effect on the treatment group, we find for each treated unit an untreated unit with the highest resemblance regarding the matching variables. To retrieve the \(ATC\), the average effect on the control group (sometimes also called \(ATU\)), we would find a treated unit for each untreated unit. Using the summary() function, we can check how well the matching works in terms of the covariate balance across the groups.
library(MatchIt)# (1) Matching# 1 vs. 1 matchingmatch_1v1<-matchit(card~pre_avg_purch+age+sex, data =membership, estimand ="ATT", method ="nearest", distance ="mahalanobis", ratio =1, replace =TRUE)summary(match_1v1)
Call:
matchit(formula = card ~ pre_avg_purch + age + sex, data = membership,
method = "nearest", distance = "mahalanobis", estimand = "ATT",
replace = TRUE, ratio = 1)
Summary of Balance for All Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max
pre_avg_purch 39.06 34.0 0.431 1.1 0.121 0.194
age 43.39 39.0 0.307 1.1 0.079 0.137
sex 0.52 0.5 0.035 . 0.017 0.017
Summary of Balance for Matched Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max Std. Pair Dist.
pre_avg_purch 39.06 38.80 0.023 1.1 0.007 0.026 0.091
age 43.39 43.09 0.021 1.1 0.008 0.029 0.098
sex 0.52 0.52 0.000 . 0.000 0.000 0.000
Sample Sizes:
Control Treated
All 547 453
Matched (ESS) 210 453
Matched 288 453
Unmatched 259 0
Discarded 0 0
The next step, the estimation, we will perform using the known lm() command. But we’ll need the matched data which includes the matched rows and the corresponding weights.
# Use matched datadf_1v1<-match.data(match_1v1)print(df_1v1)
Now, we can simply run a regression. Please note, we only include the treatment variable as a predictor, because we closed the backdoor path in the matching step.
Q4. Run the estimation step of one-vs-one matching.
Code
# (2) Estimationmod_1v1<-lm(avg_purch~card, data =df_1v1, weights =weights)summary(mod_1v1)
Call:
lm(formula = avg_purch ~ card, data = df_1v1, weights = weights)
Weighted Residuals:
Min 1Q Median 3Q Max
-62.35 -13.26 -0.87 11.37 75.78
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39.9 1.1 36.4 <2e-16 ***
card 15.2 1.4 10.9 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19 on 739 degrees of freedom
Multiple R-squared: 0.138, Adjusted R-squared: 0.137
F-statistic: 118 on 1 and 739 DF, p-value: <2e-16
Q5. Compute the \(ATC\) (or: \(ATU\)) and the \(ATE\).
Code
# ATU:# (1) Matching# 1 vs. 1 matchingmatch_1v1_atu<-matchit(card~pre_avg_purch+age+sex, data =membership, estimand ="ATC", method ="nearest", distance ="mahalanobis", ratio =1, replace =TRUE)summary(match_1v1_atu)
Call:
matchit(formula = card ~ pre_avg_purch + age + sex, data = membership,
method = "nearest", distance = "mahalanobis", estimand = "ATC",
replace = TRUE, ratio = 1)
Summary of Balance for All Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max
pre_avg_purch 39.06 34.0 0.450 1.1 0.121 0.194
age 43.39 39.0 0.328 1.1 0.079 0.137
sex 0.52 0.5 0.035 . 0.017 0.017
Summary of Balance for Matched Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max Std. Pair Dist.
pre_avg_purch 34.2 34.0 0.019 0.95 0.008 0.031 0.097
age 39.1 39.0 0.001 0.94 0.008 0.033 0.096
sex 0.5 0.5 0.000 . 0.000 0.000 0.000
Sample Sizes:
Control Treated
All 547 453
Matched (ESS) 547 197
Matched 547 288
Unmatched 0 165
Discarded 0 0
Code
# Use matched datadf_1v1_atu<-match.data(match_1v1_atu)print(df_1v1_atu)
# (2) Estimationmod_1v1_atu<-lm(avg_purch~card, data =df_1v1_atu, weights =weights)summary(mod_1v1_atu)
Call:
lm(formula = avg_purch ~ card, data = df_1v1_atu, weights = weights)
Weighted Residuals:
Min 1Q Median 3Q Max
-74.57 -11.76 0.87 12.16 66.08
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 34.844 0.791 44.0 <2e-16 ***
card 16.947 1.347 12.6 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 18 on 833 degrees of freedom
Multiple R-squared: 0.16, Adjusted R-squared: 0.159
F-statistic: 158 on 1 and 833 DF, p-value: <2e-16
Code
# ATE = p_T * ATT + p_C * ATCATE<-weighted.mean(c(mod_1v1$coefficients[2], mod_1v1_atu$coefficients[2]), c(453, 547))print(ATE)
[1] 16
One vs. many matching
Sometimes, you want to match more than just one unit. For example, imagine that you have relatively few treated units but a large amount of untreated units. To leverage all the information contained in the untreated units, matching more units might increase the validity and precision of your estimate.
Note
The R package MatchIt offers a wide range of matching methods and we only scratch the surface of what is possible. Feel free to have a look at the documentation for further information.
Q6. Run one-vs-many matching: find 3 matches for each the treated units.
Code
M<-3# (1) Matching# One-vs-many matchingmatch_1vM<-matchit(card~pre_avg_purch+age+sex, data =membership, estimand ="ATT", method ="nearest", distance ="mahalanobis", ratio =M, replace =TRUE)summary(match_1vM)
Call:
matchit(formula = card ~ pre_avg_purch + age + sex, data = membership,
method = "nearest", distance = "mahalanobis", estimand = "ATT",
replace = TRUE, ratio = M)
Summary of Balance for All Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max
pre_avg_purch 39.06 34.0 0.431 1.1 0.121 0.194
age 43.39 39.0 0.307 1.1 0.079 0.137
sex 0.52 0.5 0.035 . 0.017 0.017
Summary of Balance for Matched Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max Std. Pair Dist.
pre_avg_purch 39.06 38.71 0.030 1.1 0.008 0.037 0.13
age 43.39 43.01 0.027 1.1 0.008 0.028 0.13
sex 0.52 0.52 0.000 . 0.000 0.000 0.00
Sample Sizes:
Control Treated
All 547 453
Matched (ESS) 326 453
Matched 462 453
Unmatched 85 0
Discarded 0 0
Code
# Use matched datadf_1vM<-match.data(match_1vM)print(df_1vM)
# (2) Estimationmatchit_mod_1vM<-lm(avg_purch~card, data =df_1vM, weights =weights)summary(matchit_mod_1vM)
Call:
lm(formula = avg_purch ~ card, data = df_1vM, weights = weights)
Weighted Residuals:
Min 1Q Median 3Q Max
-59.56 -13.31 -1.38 10.49 74.44
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39.870 0.859 46.4 <2e-16 ***
card 15.300 1.222 12.5 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 18 on 913 degrees of freedom
Multiple R-squared: 0.147, Adjusted R-squared: 0.146
F-statistic: 157 on 1 and 913 DF, p-value: <2e-16
Propensity score matching
When employing approaches based on covariate-matching, you quickly run into the curse of dimensionality as your number of covariates grows. As the dimensionality grows, it becomes increasingly difficult to find suitable matches, particularly in high-dimensional spaces where finding matches can be improbable.
Consider a scenario with two covariates, each with five distinct values. In this case, observations fall into one of 25 cells defined by the covariate value grid. Now, envision ten covariates with three different values each, creating already approximately 60,000 cells. This significantly boosts the likelihood of many cells being populated by only one or zero observations, making it impossible to find matches for numerous observations.
One approach to tackle this issue is the use of propensity scores. Propensity score represents the predicted probability of treatment assignment based on matching variables. In our case, we utilize age, gender, and previous average purchases to predict the likelihood of a customer participating in the membership program. Specifically, customers who spend more on average are expected to have a higher likelihood of participation. To model this relationship, we employ logistic regression, a technique that predicts outcomes between zero and one, generating the propensity score.
Q7. Run the matching using the propensity score as the matching variable. First, for each unit, compute the propensity of being treated.
Code
# Estimate propensity to be treatedmod_ps<-glm(card~pre_avg_purch+age+sex, family =binomial(link ='logit'), data =membership)# Extract propensity scoremembership<-membership|>mutate(propensity =mod_ps$fitted)# or: mod_ps$fitted.valuessummary(membership$propensity)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.17 0.37 0.45 0.45 0.53 0.78
Q8. Having obtained the propensity score, use it as the matching variable.
Code
# (1) Matchingmatch_ps<-matchit(card~propensity, data =membership, estimand ="ATT", method ="nearest", distance ="mahalanobis", ratio =1, replace =TRUE)summary(match_ps)
Call:
matchit(formula = card ~ propensity, data = membership, method = "nearest",
distance = "mahalanobis", estimand = "ATT", replace = TRUE,
ratio = 1)
Summary of Balance for All Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max
propensity 0.48 0.43 0.44 1.2 0.12 0.2
Summary of Balance for Matched Data:
Means Treated Means Control Std. Mean Diff. Var. Ratio eCDF Mean eCDF Max Std. Pair Dist.
propensity 0.48 0.48 0 1 0.001 0.015 0.008
Sample Sizes:
Control Treated
All 547 453
Matched (ESS) 186 453
Matched 262 453
Unmatched 285 0
Discarded 0 0
Code
# Equivalent:# match_ps2 <- matchit(# card ~ propensity,# data = membership,# estimand = "ATT",# ratio = 1,# replace = TRUE# )# Use matched datadf_ps<-match.data(match_ps)print(df_ps)
# (2) Estimationmod_ps<-lm(avg_purch~card, data =df_ps, weights =weights)summary(mod_ps)
Call:
lm(formula = avg_purch ~ card, data = df_ps, weights = weights)
Weighted Residuals:
Min 1Q Median 3Q Max
-59.56 -13.29 -0.06 11.43 123.33
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39.63 1.18 33.6 <2e-16 ***
card 15.54 1.48 10.5 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19 on 713 degrees of freedom
Multiple R-squared: 0.134, Adjusted R-squared: 0.132
F-statistic: 110 on 1 and 713 DF, p-value: <2e-16
Note
Instead of running a separate logistic regression to compute the propensity scores, you could also provide the arguments method = "glm" and link = "logit" to the matchit() function.
It’s important to note that while propensity score matching effectively mitigates the curse of dimensionality, a fundamental issue arises: having the same propensity score does not guarantee that observations share identical covariate values. Conversely, identical covariate values do imply the same propensity score. This inherent asymmetry raises concerns among prominent statisticians, leading to criticism of propensity score matching as a robust identification strategy.1
Inverse probability weighting
Step-by-step approach
Instead inverse probability weighting (IPW) has proven to be a more precise method than matching approaches, particularly when the sample is large enough. So what do we do with the probability/propensity scores in IPW? We use the propensity score of an observation unit to increase or decrease its weights and thereby make some observations more important than others. The weight obtains as
where only one of the terms is always active as \(D_i\) is either one or zero. \(\pi_i\) denotes the propensity. Now we should better understand what “inverse probability weighting” actually means. It weights each observation by its inverse of its treatment probability. Let’s proceed to calculate this for our dataset.
Q9. Given the formula, calculate the weights for each observation.
Code
# Calculate inverse probability weightsmembership<-membership|>mutate(ipw =(card/propensity)+(1-card)/(1-propensity))summary(membership$ipw)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.2 1.6 1.9 2.0 2.3 4.4
We need to provide these calculated weights as an additional argument to lm() using the weights argument.
Code
# Regression with inverse probability weightingmodel_ipw<-lm(avg_purch~card, data =membership, weights =ipw)summary(model_ipw)
Call:
lm(formula = avg_purch ~ card, data = membership, weights = ipw)
Weighted Residuals:
Min 1Q Median 3Q Max
-107.34 -18.56 -0.18 17.59 128.59
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.245 0.847 44.0 <2e-16 ***
card 15.413 1.197 12.9 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 27 on 998 degrees of freedom
Multiple R-squared: 0.142, Adjusted R-squared: 0.142
F-statistic: 166 on 1 and 998 DF, p-value: <2e-16
Integrated approach
For demonstration and learning purpose, we split the procedure in two steps but there are external packages which combine both steps, e.g. the causalweight package and the function treatweight().
library(causalweight)# IPW estimationmodel_ipw_int<-treatweight( y =membership$avg_purch, d =membership$card, x =membership[, c("pre_avg_purch", "age", "sex")])model_ipw_int
Accept the Week 4 - Assignment and follow the same steps as last week and as described in the organization chapter.
Regression Adjustment
When discussing your results from the regression adjustment for the sales of light jackets with your team, one of your analysts comes up with the idea to include temperature at the customers location into your analysis. Because you know the customer’s location, you can check the temperature and add it to the data. Load the data prices_new.rds.
Check whether adjusting for temperature improves your analysis using e.g. \(R^2\) or hypothesis tests.
Do you think the relationship between sales and temperature is linear? Or do you suspect a non-linear relationship? Please argue, whether including a quadratic term into the functional form by y ~ x + I(x^2) + ... makes sense?
Matching
For the next tasks, you are going to use the data set health_program.rds, which you should already be familiar with from the assignment two weeks ago. Identify the matching variables and perform
one-vs-one nearest-neighbor matching for \(ATT\) and \(ATU\),
and propensity score matching for \(ATE\).
Look at the matched data frames and explain the different number of rows.
Inverse probability weighting
Run a logistic regression to estimate the treatment propensity.
Add the propensity scores to your data frame, compute the inverse probability weights and sort your data frame by them by running df |> arrange(var) or df |> arrange(-var). Take a look at the units with the highest or lowest weights. What do you notice? Use the logistic regression summary to argue why these observations have such high/low weights.
Run the regression based on the calculated weights and compare it to the estimates from the matching estimators.