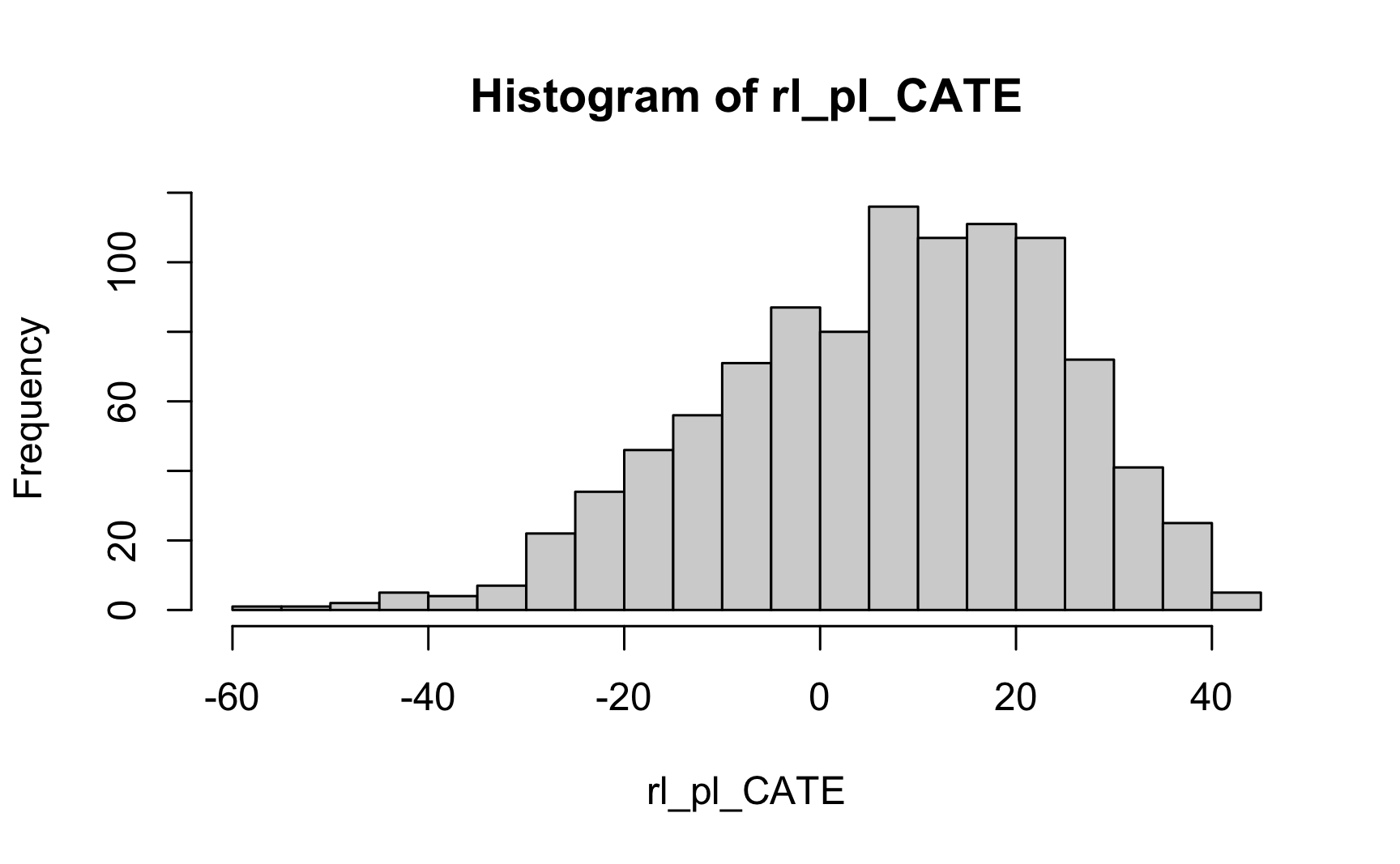
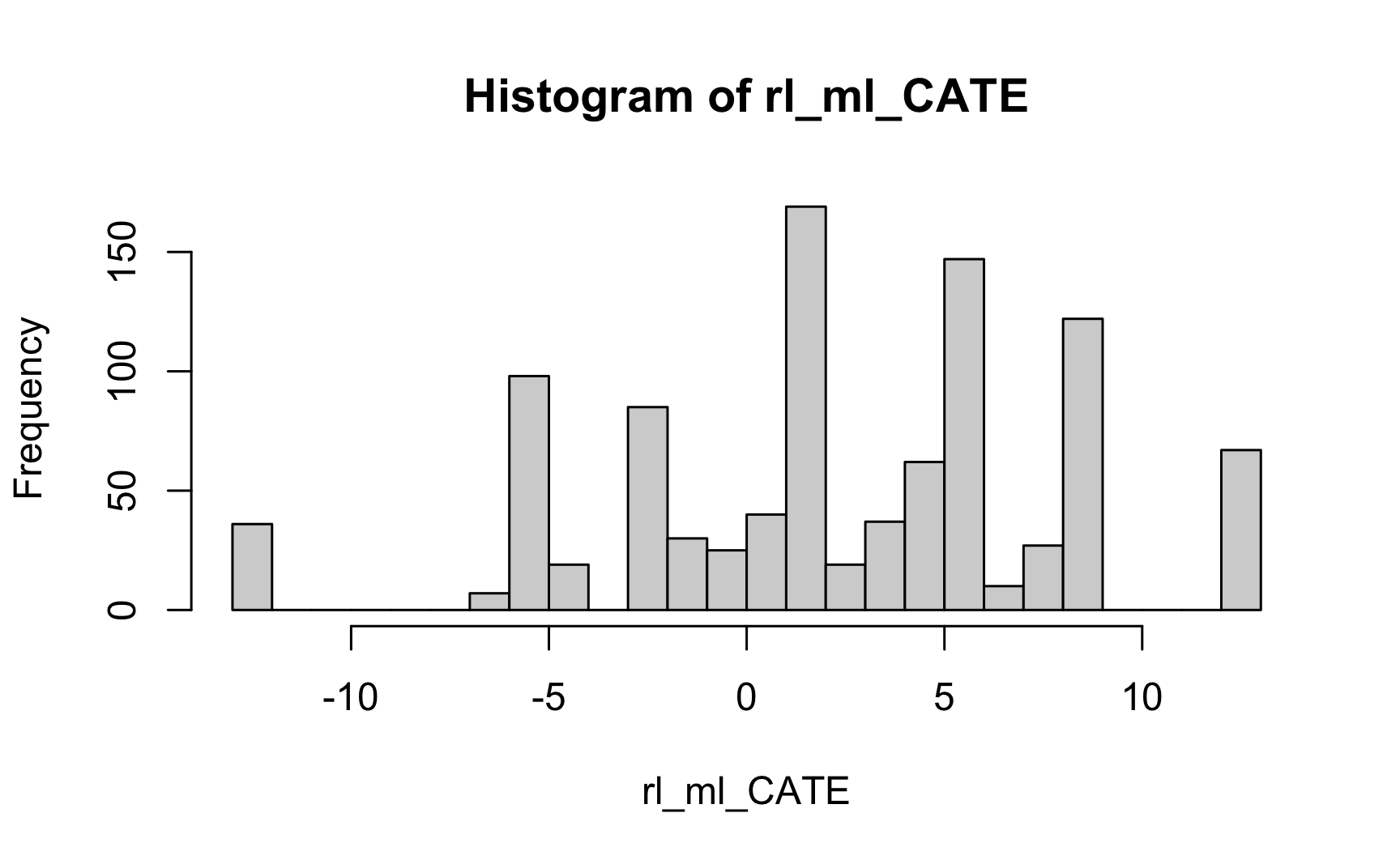
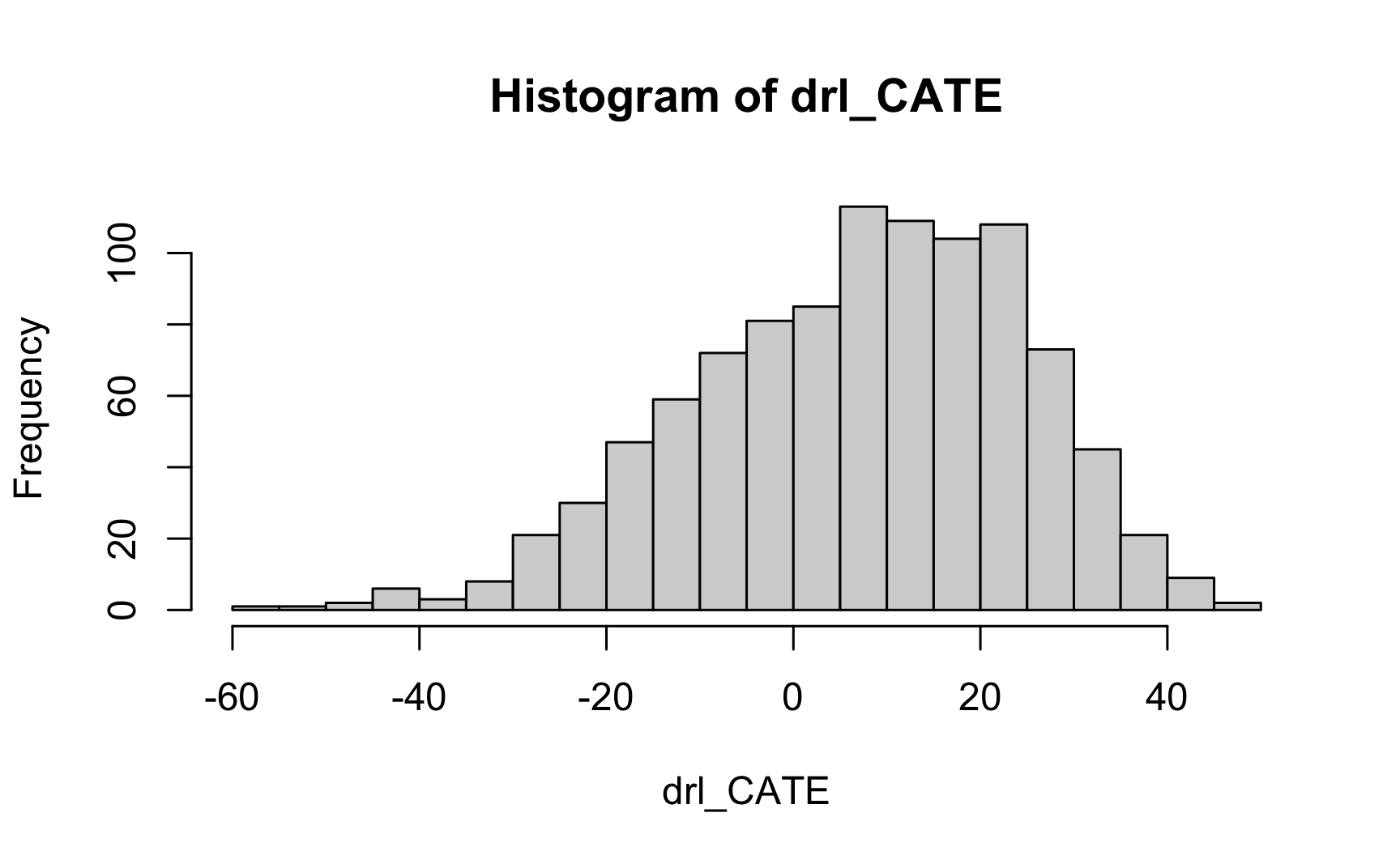
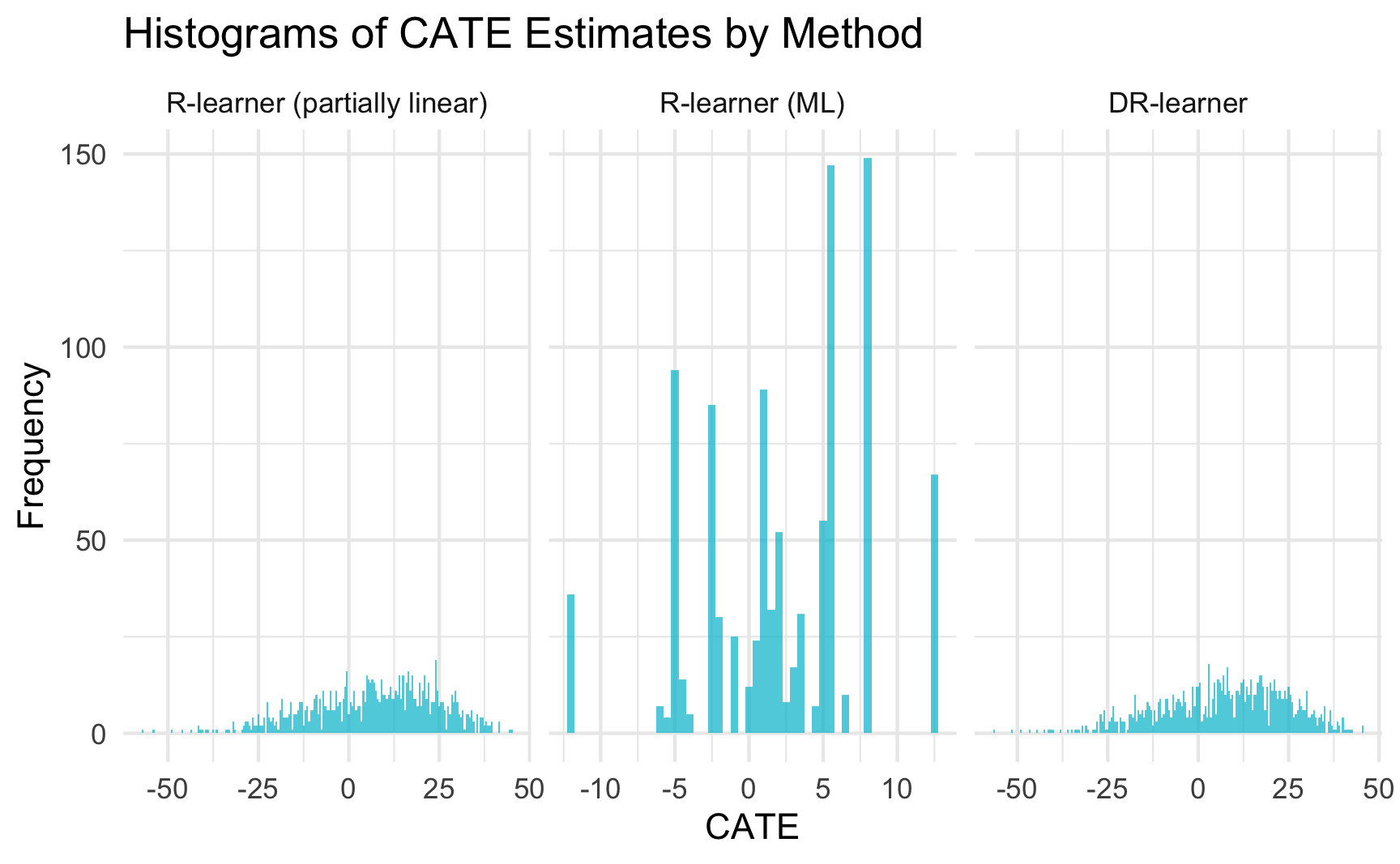
Rows: 1,000
Columns: 27
$ age <dbl> 32, 42, 23, 67, 27, 54, 40, 27, 29, 35, 22, 37, 25, 41, 37, 60, 32, 31, 30, 41, 34, 48, 42, 41, 38, 29, 37, 27, 26, 27, 5…
$ sex <int> 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0…
$ pre_avg_purch <dbl> 22, 32, 32, 47, 30, 31, 38, 26, 26, 47, 36, 55, 32, 26, 48, 41, 23, 23, 33, 30, 31, 25, 43, 37, 22, 40, 33, 24, 23, 37, 3…
$ card <int> 1, 0, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1…
$ avg_purch <dbl> 45.45, 72.73, 64.20, 55.66, 80.08, 35.34, 10.22, 45.32, 0.56, 69.84, 53.71, 55.46, 53.50, 44.00, 29.72, 33.08, 32.08, 37.…
$ vehicle <int> 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ food <int> 1, 2, 0, 1, 1, 0, 1, 0, 0, 0, 2, 0, 1, 2, 1, 0, 0, 1, 1, 2, 1, 2, 4, 1, 0, 2, 2, 0, 0, 2, 1, 2, 2, 2, 2, 2, 1, 0, 1, 1, 1…
$ beverage <int> 2, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 1, 2, 1, 0, 3, 0, 0, 1, 0, 1, 4, 0, 2, 3, 1, 1, 2, 2, 1, 1, 1, 1, 2, 0, 1, 1, 0, 2, 1, 0…
$ art <int> 0, 2, 1, 2, 1, 0, 0, 1, 1, 1, 3, 0, 0, 3, 1, 3, 1, 0, 0, 0, 2, 1, 2, 1, 1, 1, 1, 0, 1, 2, 3, 0, 2, 0, 2, 0, 1, 0, 1, 2, 0…
$ baby <int> 1, 1, 1, 1, 1, 1, 2, 1, 3, 1, 2, 0, 1, 2, 0, 0, 0, 2, 0, 0, 0, 1, 0, 1, 2, 2, 3, 1, 1, 0, 1, 2, 0, 2, 0, 0, 2, 2, 0, 1, 1…
$ personal_care <int> 0, 0, 2, 1, 1, 1, 3, 1, 1, 0, 1, 1, 0, 0, 1, 0, 2, 0, 1, 1, 0, 1, 2, 1, 0, 2, 0, 0, 3, 2, 1, 1, 1, 2, 0, 1, 0, 3, 1, 2, 1…
$ toys <int> 0, 0, 3, 2, 1, 1, 1, 2, 2, 0, 0, 1, 2, 3, 0, 1, 1, 0, 1, 2, 1, 0, 1, 0, 1, 0, 0, 0, 2, 0, 1, 2, 3, 0, 1, 0, 1, 1, 1, 1, 1…
$ clothing <int> 2, 1, 2, 2, 2, 1, 1, 2, 2, 2, 5, 1, 1, 1, 1, 3, 0, 1, 2, 2, 5, 2, 3, 1, 2, 1, 1, 0, 0, 1, 0, 0, 2, 5, 1, 0, 3, 1, 1, 2, 1…
$ decor <int> 0, 0, 0, 3, 2, 2, 0, 1, 1, 0, 2, 0, 0, 2, 1, 1, 0, 1, 0, 2, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 3, 1, 2, 2, 2, 0, 0, 1, 1, 2…
$ cell_phones <int> 1, 2, 4, 1, 1, 2, 4, 4, 3, 1, 5, 1, 3, 2, 3, 4, 3, 3, 1, 4, 3, 5, 2, 4, 5, 5, 5, 4, 2, 4, 2, 2, 2, 3, 5, 3, 3, 2, 3, 4, 1…
$ construction <int> 1, 2, 1, 1, 1, 4, 1, 0, 3, 0, 0, 0, 2, 1, 0, 0, 2, 0, 0, 0, 1, 2, 1, 2, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 3, 1, 2, 1, 1, 3…
$ home_appliances <int> 0, 2, 0, 1, 1, 0, 1, 0, 0, 2, 1, 0, 0, 0, 2, 0, 1, 1, 1, 2, 0, 1, 0, 1, 1, 0, 2, 0, 3, 0, 1, 4, 1, 1, 1, 0, 1, 2, 1, 2, 2…
$ electronics <int> 1, 2, 4, 0, 2, 2, 1, 2, 2, 3, 1, 3, 3, 0, 4, 1, 2, 1, 2, 2, 2, 0, 2, 2, 0, 2, 4, 0, 0, 2, 4, 2, 2, 1, 0, 2, 1, 1, 0, 3, 2…
$ sports <int> 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 2, 4, 0, 2, 0, 3, 2, 0, 1, 0, 1, 2, 3, 4, 0, 2, 1, 1, 0, 1, 0, 1, 2…
$ tools <int> 3, 2, 1, 1, 1, 2, 1, 0, 4, 2, 1, 0, 0, 2, 0, 1, 1, 2, 2, 0, 0, 1, 1, 0, 0, 0, 0, 2, 1, 0, 1, 0, 3, 0, 0, 1, 0, 2, 1, 0, 0…
$ games <int> 4, 1, 3, 1, 2, 1, 3, 1, 0, 3, 0, 1, 1, 7, 1, 3, 0, 1, 2, 3, 0, 2, 2, 1, 2, 6, 3, 1, 2, 1, 0, 2, 2, 2, 2, 2, 2, 3, 2, 2, 2…
$ industry <int> 0, 0, 2, 0, 0, 1, 0, 0, 3, 2, 1, 2, 1, 0, 0, 2, 1, 0, 3, 0, 0, 0, 3, 1, 3, 0, 1, 3, 2, 0, 2, 0, 2, 1, 1, 0, 0, 2, 0, 2, 1…
$ pc <int> 4, 2, 2, 2, 3, 0, 2, 1, 3, 0, 3, 2, 3, 3, 2, 1, 0, 0, 3, 2, 3, 2, 1, 1, 3, 1, 3, 2, 2, 0, 2, 4, 2, 1, 0, 0, 4, 2, 3, 2, 0…
$ jewel <int> 0, 1, 0, 0, 0, 2, 0, 0, 0, 4, 1, 0, 0, 1, 3, 1, 0, 3, 1, 4, 0, 1, 2, 0, 1, 2, 2, 2, 2, 0, 1, 1, 0, 2, 0, 0, 1, 4, 0, 1, 1…
$ books <int> 2, 1, 0, 0, 1, 0, 0, 0, 4, 2, 1, 2, 1, 2, 0, 1, 0, 0, 0, 3, 0, 3, 1, 2, 2, 2, 2, 1, 0, 1, 2, 1, 1, 1, 1, 0, 0, 3, 0, 2, 1…
$ music_books_movies <int> 1, 3, 3, 2, 2, 1, 1, 0, 2, 2, 0, 0, 2, 3, 2, 0, 1, 0, 2, 1, 0, 1, 2, 1, 1, 0, 0, 1, 2, 0, 1, 0, 2, 0, 2, 1, 2, 0, 1, 0, 0…
$ health <int> 0, 0, 2, 2, 6, 0, 4, 2, 2, 2, 2, 0, 3, 1, 0, 2, 3, 2, 1, 3, 4, 2, 3, 1, 2, 1, 5, 3, 2, 2, 5, 1, 5, 2, 1, 0, 0, 4, 5, 4, 3…