Another quasi-experimental method from our toolbox is the difference-in-differences (DiD) approach. It is the most popular research design in quantitative and social sciences. As the name implies, the method captures differences by observing a treatment and a control group over time to estimate causal average effects.
In its simplest form, DiD compares two groups (control and treatment) at two points in time (before treatment and after) by observing if and how different both groups change. It is important to note, that both groups do not need to be equal before the treatment.
By taking two differences, two different kind of biases can be avoided. First, by comparing both groups at both points in time, any external effect that affects the outcome of both groups in the same way is equalized. Secondly, taking only the difference of a change in consideration, we can disregard selection bias. Potential outcomes can differ:
\[
E[Y_0|D = 0] \gtreqqless E[Y_0|D = 1]
\]
We don’t care whether initially treatment and control group are different. We only assume that they behave similarly in absence of treatment.
As can be seen in the table, the difference in outcome for the treatment group before and after treatment is \(D + T\), while for the control group it is only \(T\). The difference of these two differences then reduces to only \(D\), which is the treatment effect we want to estimate.
Again, opposed to methods where we just know one outcome - the “after” outcome, regardless of whether a unit received or did not receive treatment - we do not have to assume that the potential outcomes \(E[Y_0|D=1] = E[Y_0|D=1]\) are equal. That is a big difference, because do not have to assume that observation units are similar in all their characteristics.
Instead DiD hinges on a different assumption, the parallel trends assumption. It says that, in absence of treatment for both groups, they would be expected to evolve similarly over time. In other words, we do not expect the potential outcome to be similar, but only the change of outcomes from before to after. It implies that there is no factor that has only an impact on just one of the groups. If units differ in characteristics, they are only allowed to have a constant effect. If the effect varies with time, the parallel trends assumption is violated.
Application
Illustrating the parallel trends assumption is very helpful. By going through two scenarios, we will look at an example where parallel trends are fulfilled and another one where it is violated.
Scenario A: parallel trends assumption fulfilled
Scenario B: parallel trends assumption violated
Let’s imagine, you are manager of a company that has two stores, one of them being in City 1 and the other being in City 2. You want to test the effectiveness of a local ad campaign on sales. Therefore, you will run a campaign at the store in City 1 but not in City 2 and keep track of sales in the periods before and after the treatment.
You don’t need to read follow all steps how to generate data for both scenarios, but I’ll leave it in for those who are interested.
Data Simulation
\(Y\) - sales
\(D\) - true treatment effect
\(P\) - periods
\(S\) - store index
\(X\) - covariate, e.g. ecosystem
With the function generate_data() we generate data with arbitrary values for the number of stores, number of observed periods, the size of the true treatment effect, the timing of treatment and level of noise in the data generating process. Data is generated for both scenarios as can be seen at the suffixes.
Function to simulate DiD data
# Load tidyverse packagelibrary(tidyverse)# Function to simulate datagenerate_data<-function(S=2, # number of groupsP=10, # number of periodsD_size=1, # effect of treatmentD_time=NULL, # time of treatmenty_0=50, # base value for ysd=1, # standard deviations for randomly generated sequencesscenario=c("A", "B")){# create group period dyadss<-rep(0:1, each =P)p<-rep(1:P, S)# timing and size of treatment (effect)delta<-D_sizeif(missing(D_time))D_time<-P/2after<-as.numeric(ifelse(p>D_time, 1, 0))# create relation between independent variables and treatment (actually# other way round, but easier to simulate this way)x1<-rnorm(S*P, s, sd)# create dependent variable ...# ... for scenario (A)y_a<-y_0+delta*s*after+1/5*p+x1+rnorm(S*P, 0, sd)# ... for scenario (B)y_b<-y_0+delta*s*after+1/5*p+x1+s*x1+1/3*p*x1+rnorm(S*P, 0, sd)# add variables to tabledf<-tibble( treat =s, period =p, after =after, x1 =x1, sales =if(scenario=="A"){y_a}else{y_b})# return tablereturn(df)}
We choose to generate a data set with a true treatment effect of 1 and 10 observed periods. For now, we just have one store as a treated unit and one store as a non-treated unit. Later, we will extend it to a larger number of stores per group, but for demonstration purpose, we restrict it to two stores, initially. We have 10 periods with 5 periods before and 5 after treatment. Lastly, we add a little bit of noise.
# Generate one sample for each scenarioP<-10# number of periodsdelta<-1# true treatment effect# Scenario Adf_A<-generate_data(P =P, D_size =delta, sd =0.01, scenario ="A")# Scenario Bdf_B<-generate_data(P =P, D_size =delta, sd =0.01, scenario ="B")
Parallel trends
Scenario A
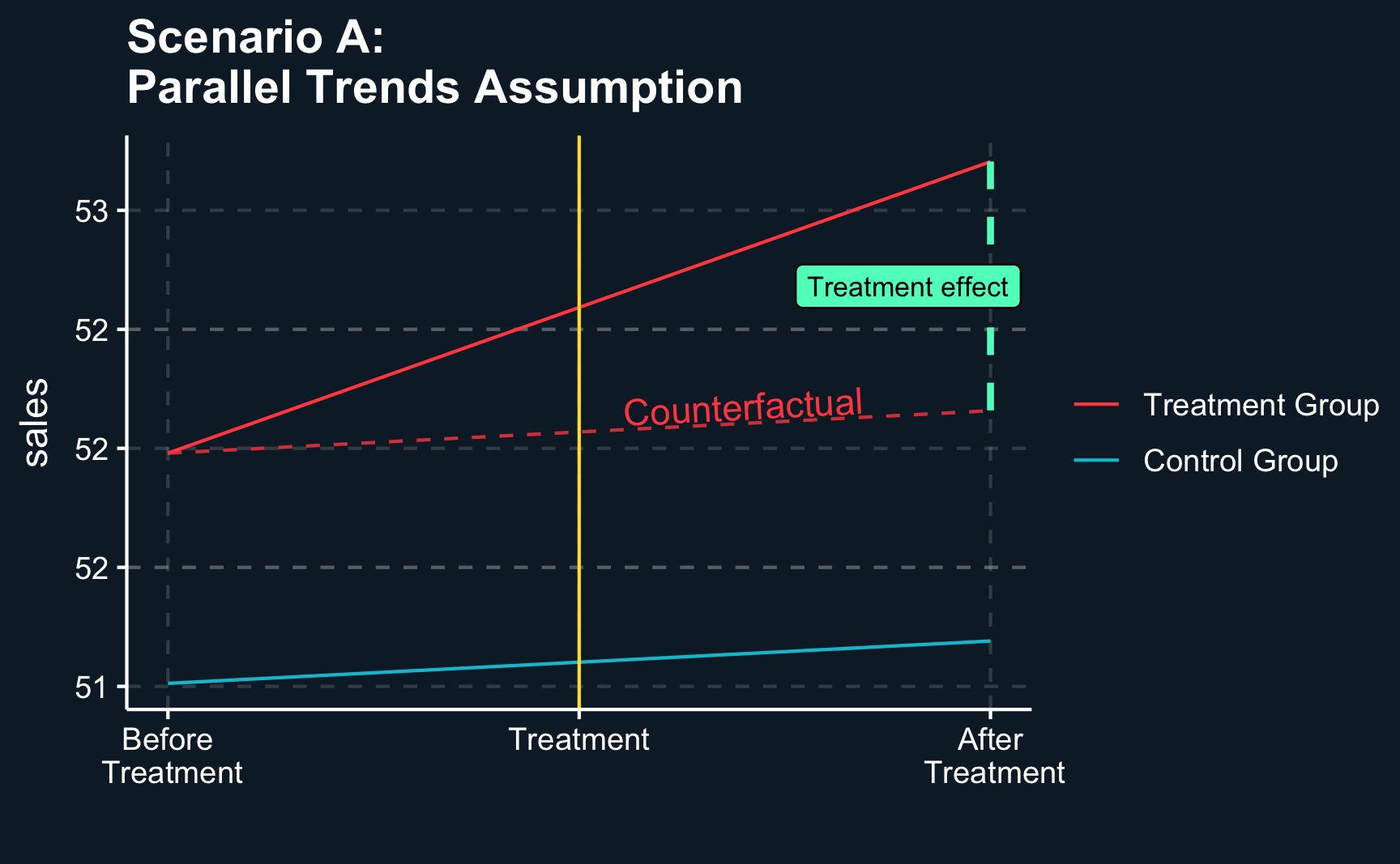
To compute an estimated treatment effect, we filter the data to the two periods just around treatment and implement the formulas as in the introduction. Not surprisingly, we get an estimate that is very close to our true treatment effect.
# [1.1.1] (A) Fulfillment ----# Scenario (A)# Only show last data point before and first data point after treatment.df_A_zoom_in<-df_A%>%filter(period%in%(P/2):(P/2+1))# Manually compute differences# Step 1: Difference between treatment and control group BEFORE treatmentbefore_control_A<-df_A_zoom_in%>%filter(treat==0, after==0)%>%pull(sales)before_treatment_A<-df_A_zoom_in%>%filter(treat==1, after==0)%>%pull(sales)diff_before_A<-before_treatment_A-before_control_A# Step 2: Difference between treatment and control group AFTER treatmentafter_control_A<-df_A_zoom_in%>%filter(treat==0, after==1)%>%pull(sales)after_treatment_A<-df_A_zoom_in%>%filter(treat==1, after==1)%>%pull(sales)diff_after_A<-after_treatment_A-after_control_A# Step 3: Difference-in-differences. Unbiased estimate if parallel trends is # correctly assumed and there is no hidden confounding. Estimate may vary from # true treatment effect, as we also include some noise in the data generating # process.diff_diff_A<-diff_after_A-diff_before_Asprintf("Estimate: %.2f, True Effect: %.2f", diff_diff_A, delta)
[1] "Estimate: 1.05, True Effect: 1.00"
Looking at the last period before and the first period after treatment, the impact of treatment can clearly be seen. The dashed line represents the counterfactual value for the treated group, i.e. the value it would have if it had not been treated. This value is not observed, but by the parallel trends assumptions, it would have developed like the value for the untreated group.
Plots in this chapter
Generating the plots for this chapter is a bit tricky as they contain a lot of annotations and other extensions. I left the code for those who want to replicate it. But you do not worry if you cannot reproduce them.
Plot parallel trends assumption
# Compute counterfactual sales for treated groupcf_treat_A<-df_A[!df_A$treat==1, "sales"]+diff_before_Adf_A[df_A$treat==1, "sales_cf"]<-cf_treat_A# Add to zoomed in tabledf_A_zoom_in<-df_A_zoom_in%>%left_join(df_A)# Plot DiD with parallel trends assumptionggplot(df_A_zoom_in, aes(x =period, y =sales, color =as.factor(treat)))+# Geographic elementsgeom_line()+geom_vline(xintercept =P/2+.5, color =ggthemr::swatch()[5])+geom_line(data =df_A_zoom_in%>%filter(treat==1),aes(x =period, y =sales_cf), color =ggthemr::swatch()[3], alpha =.8, linetype ="dashed")+annotate(geom ="segment", x =(P/2+1), xend =(P/2+1), y =after_treatment_A, yend =after_treatment_A-diff_diff_A, linetype ="dashed", color =ggthemr::swatch()[4], linewidth =1)+annotate(geom ="label", x =(P/2)+0.9, y =after_treatment_A-(diff_diff_A/2), label ="Treatment effect", size =3, fill =ggthemr::swatch()[4])+annotate(geom ="text", x =(P/2)+0.7, y =before_control_A+1.1*diff_before_A+.1, label ="Counterfactual", size =4, angle =3, color =ggthemr::swatch()[3])+# Custom scaling and legendscale_x_continuous(name ="", breaks=c(5, 5.5, 6), labels =c("Before\n Treatment", "Treatment","After\n Treatment"))+scale_color_discrete(labels =c("Control Group", "Treatment Group"))+guides(colour =guide_legend(reverse =T))+theme(legend.title =element_blank())+ggtitle("Scenario A:\nParallel Trends Assumption")
If parallel trends assumption can be assumed, treatment effect is valid. Counterfactual line shows how outcome would have been evolved in absence of treatment.
Scenario B
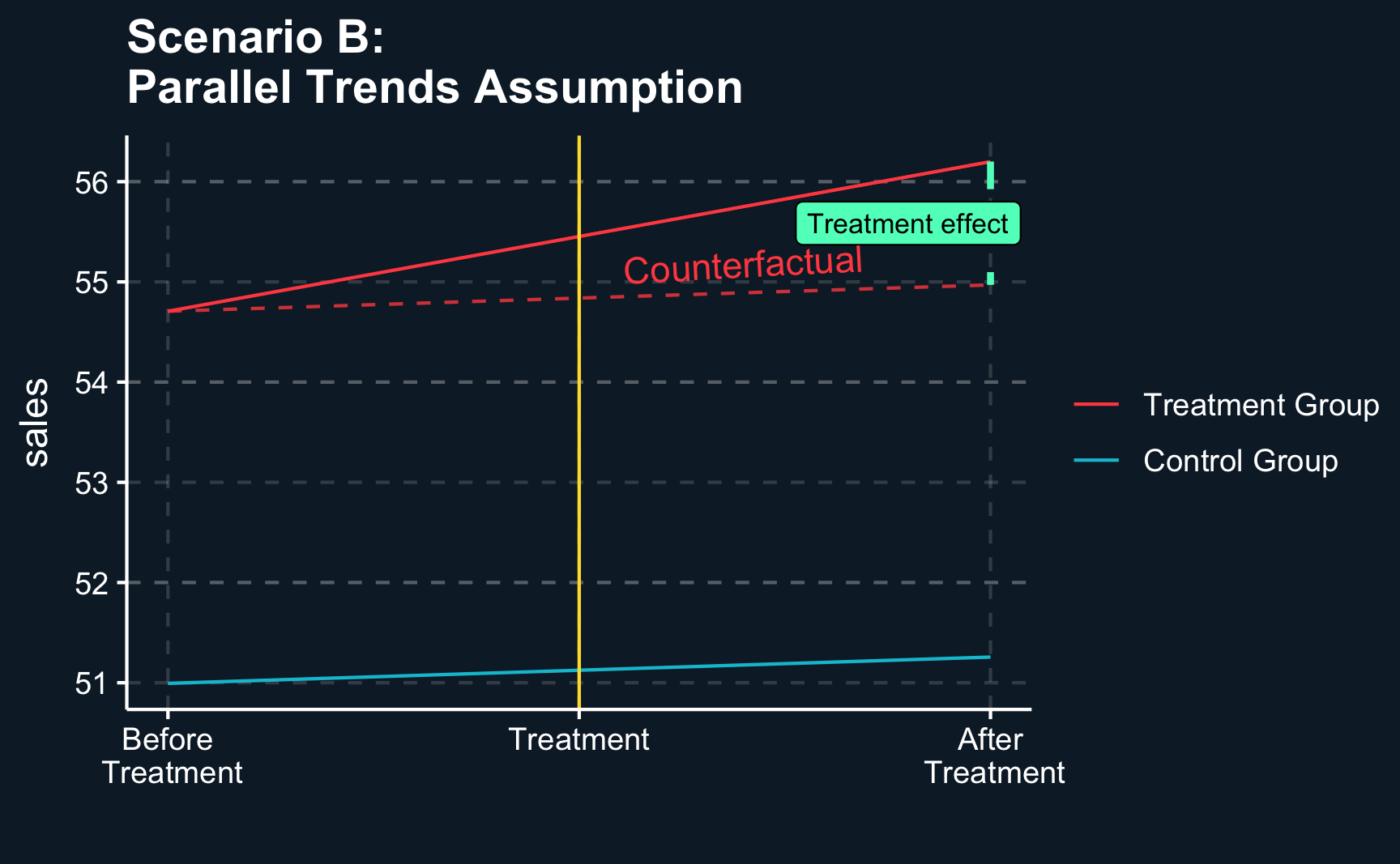
Repeating the steps for scenario B yields an unexpected result. The estimated treatment effect is different from what we would have expected.
# [1.1.2] (B) Violation ----# Scenario (B)# Only show last data point before and first data point after treatment.df_B_zoom_in<-df_B%>%filter(period%in%(P/2):(P/2+1))# Manually compute differences# Step 1: Difference between treatment and control group BEFORE treatmentbefore_control_B<-df_B_zoom_in%>%filter(treat==0, after==0)%>%pull(sales)before_treatment_B<-df_B_zoom_in%>%filter(treat==1, after==0)%>%pull(sales)diff_before_B<-before_treatment_B-before_control_B# Step 2: Difference between treatment and control group AFTER treatmentafter_control_B<-df_B_zoom_in%>%filter(treat==0, after==1)%>%pull(sales)after_treatment_B<-df_B_zoom_in%>%filter(treat==1, after==1)%>%pull(sales)diff_after_B<-after_treatment_B-after_control_B# Step 3: Difference-in-differences. Unbiased estimate if parallel trends is # correctly assumed and there is no hidden confounding. Estimate varies from # true treatment effect due to confounding and added noise.diff_diff_B<-diff_after_B-diff_before_Bsprintf("Estimate: %.2f, True Effect: %.2f", diff_diff_B, delta)
[1] "Estimate: 1.23, True Effect: 1.00"
Again, the picture is very similar. Having only four data points, treatment before and after and control before and after, there is no way to test the parallel trends assumption which leaves room for doubt. So how can we check whether we made a mistake or the parallel trends assumption is violated?
Plot parallel trends assumption
# Compute counterfactual sales for treated groupcf_treat_B<-df_B[!df_B$treat==1, "sales"]+diff_before_Bdf_B[df_B$treat==1, "sales_cf"]<-cf_treat_B# Add to zoomed in tabledf_B_zoom_in<-df_B_zoom_in%>%left_join(df_B)# Plot DiD with parallel trends assumptionggplot(df_B_zoom_in, aes(x =period, y =sales, color =as.factor(treat)))+# Geographic elementsgeom_line()+geom_vline(xintercept =P/2+.5, color =ggthemr::swatch()[5])+geom_line(data =df_B_zoom_in%>%filter(treat==1),aes(x =period, y =sales_cf), color =ggthemr::swatch()[3], alpha =.8, linetype ="dashed")+annotate(geom ="segment", x =(P/2+1), xend =(P/2+1), y =after_treatment_B, yend =after_treatment_B-diff_diff_B, linetype ="dashed", color =ggthemr::swatch()[4], linewidth =1)+annotate(geom ="label", x =(P/2)+0.9, y =after_treatment_B-(diff_diff_B/2), label ="Treatment effect", size =3, fill =ggthemr::swatch()[4])+annotate(geom ="text", x =(P/2)+0.7, y =before_control_B+1.1*diff_before_B+.1, label ="Counterfactual", size =4, angle =3, color =ggthemr::swatch()[3])+# Custom scaling and legendscale_x_continuous(name ="", breaks=c(5, 5.5, 6), labels =c("Before\n Treatment", "Treatment","After\n Treatment"))+scale_color_discrete(labels =c("Control Group", "Treatment Group"))+guides(colour =guide_legend(reverse =T))+theme(legend.title =element_blank())+ggtitle("Scenario B:\nParallel Trends Assumption")
Knowing the true treatment effect, we know that the estimated treatment effect is too high. But this plot can’t tell us why.
Event Study
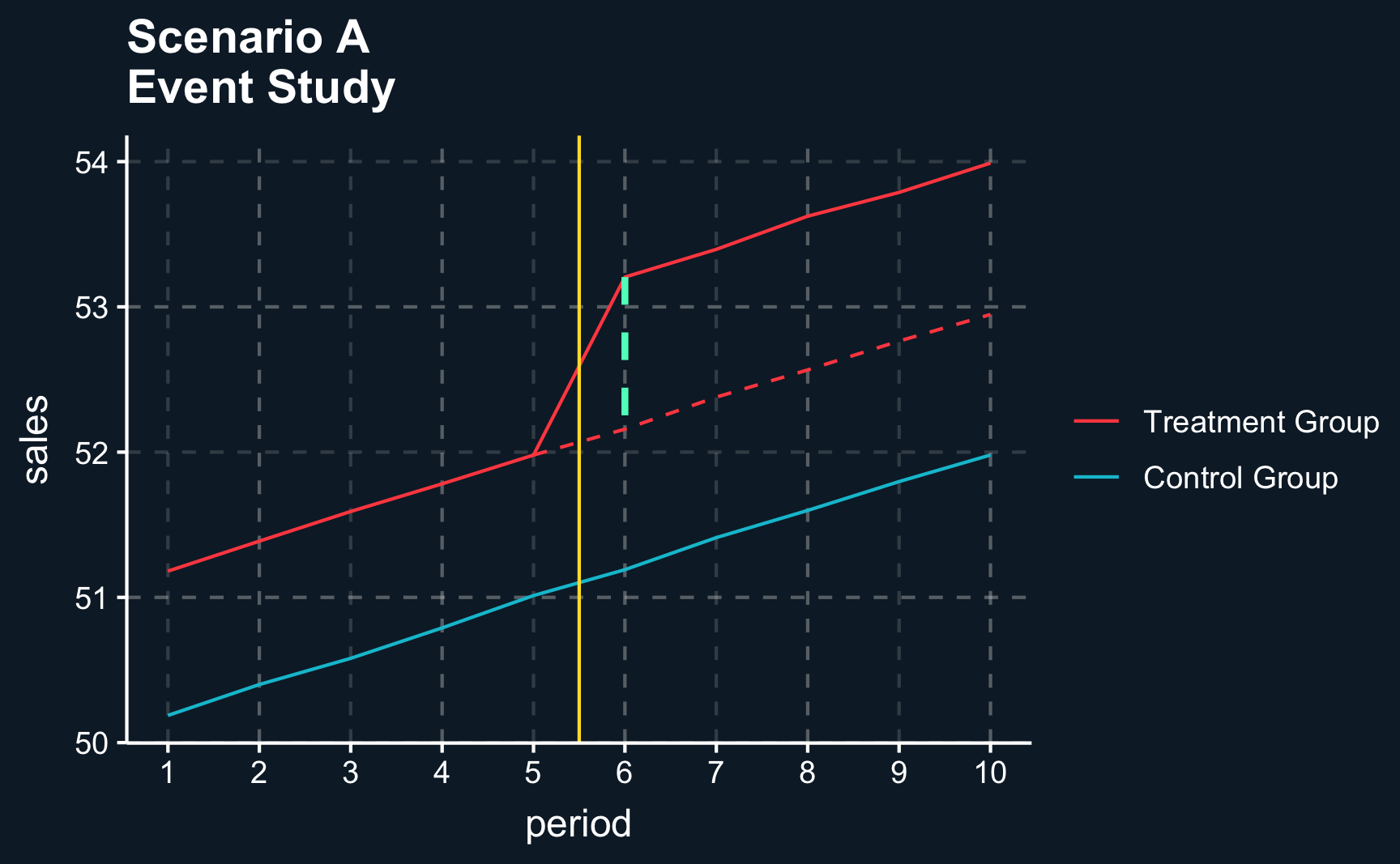
Hence, numerous researchers endeavor to enhance the reliability of their findings through the utilization of an event study. Comparing trends before treatment across treatment and control group, it should show that there was no difference prior to the treatment. Because if there was no difference before treatment, why should there be difference after the treatment (if not for the treatment itself)?
However, event studies cannot provide full certainty about the parallel trends assumption. There still might be other unobserved factors that could affect the treatment. But still, it is a good way to argue that treatment and control group are comparable.
Code: Event Study A
# [1.2] Event study ----# To provide evidence of the credibility in assuming parallel trends, # researchers often perform an event study, if possible. Instead of only# looking at the last period before and the first period after treatment,# further periods are included to examine the validity of the parallel trends# assumption and the treatment effect estimate.# [1.2.1] (A) Fulfillment ----# Zoom out and show that parallel trend assumption is fulfilled in scenario (a)# Compute difference in control groupdiff_control_A<-after_control_A-before_control_A# Plot event studyev_stdy_A<-ggplot(df_A, aes(x =period, y =sales, color =as.factor(treat)))+geom_line()+geom_vline(xintercept =P/2+.5, color =ggthemr::swatch()[5])+geom_line(data =df_A%>%filter(treat==1, period>=P/2),aes(x =period, y =sales_cf), color =ggthemr::swatch()[3], linetype ="dashed")+annotate(geom ="segment", x =(P/2+1), xend =(P/2+1), y =after_treatment_A, yend =after_treatment_A-diff_diff_A, linetype ="dashed", color =ggthemr::swatch()[4], linewidth =1)+# Custom scaling and legendscale_x_continuous(breaks =1:P)+scale_color_discrete(labels =c("Control Group", "Treatment Group"))+guides(colour =guide_legend(reverse =T))+theme(legend.title =element_blank())+ggtitle("Scenario A\nEvent Study")
Code: Event Study B
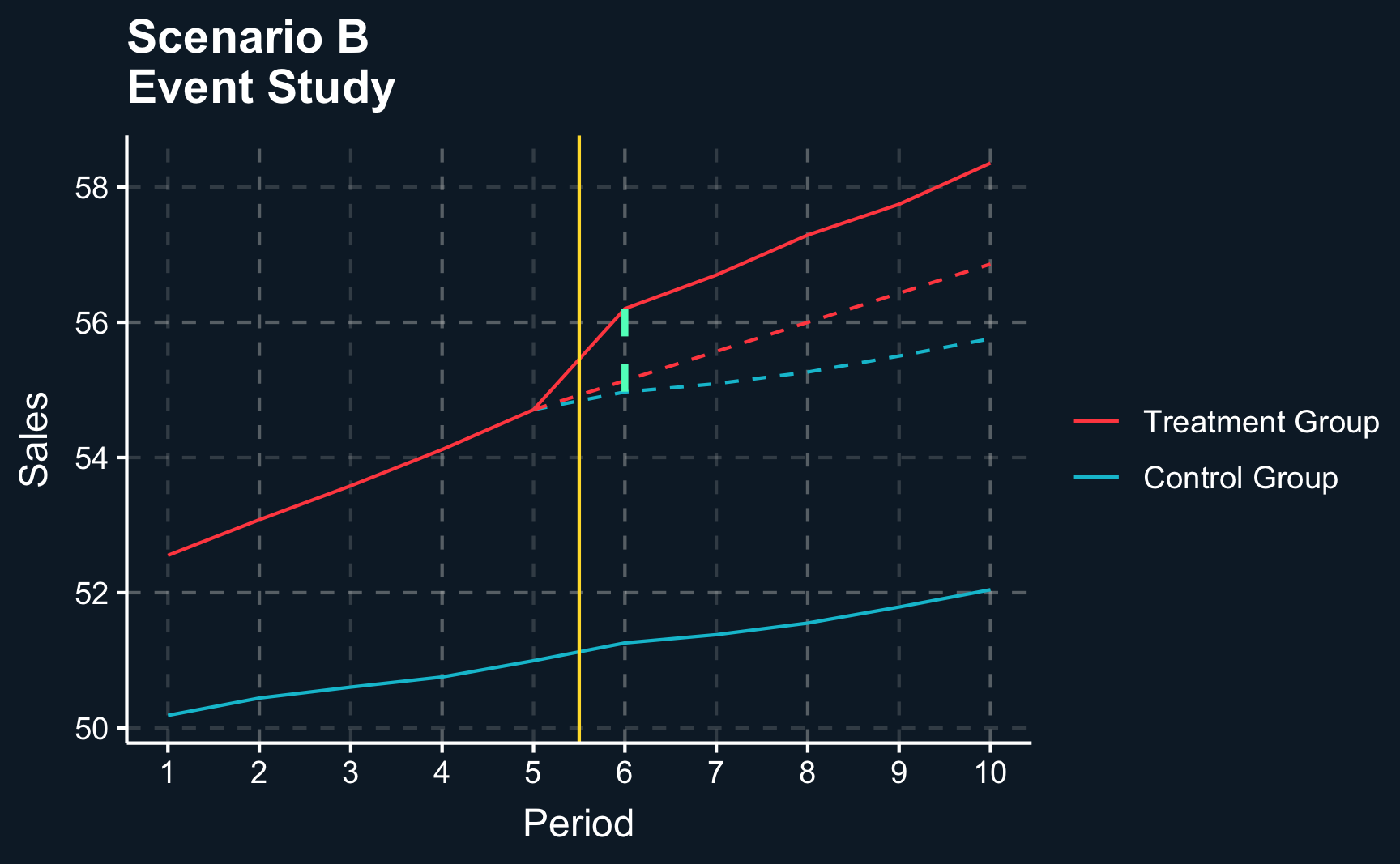
# [1.2.2] (B) Violation----# Zoom out and show that parallel trend assumption is violated in scenario (b)# Compute difference in treatment group# Before treatmentdiff_control_B<-after_control_B-before_control_B# Increase from t0 to before treatmentinit_treatment_B<-df_B%>%filter(treat==1, period==1)%>%pull(sales)diff_treatment_B<-(before_treatment_B-init_treatment_B)/(P/2)# Plot event studyev_stdy_B<-ggplot(df_B, aes(x =period, y =sales, color =as.factor(treat)))+geom_line()+geom_vline(xintercept =P/2+.5, color =ggthemr::swatch()[5])+geom_line(data =df_B%>%filter(treat==1, period>=P/2),aes(x =period, y =sales_cf), color =ggthemr::swatch()[2], linetype ="dashed")+annotate(geom ="segment", x =(P/2), xend =P, y =before_treatment_B, yend =before_treatment_B+(P/2)*(diff_treatment_B), linetype ="dashed", color =ggthemr::swatch()[3])+# Estimated treatment effectannotate(geom ="segment", x =(P/2+1), xend =(P/2+1), y =after_treatment_B, yend =after_treatment_B-diff_diff_B, linetype ="dashed", color =ggthemr::swatch()[4], linewidth =1)+# Custom scaling and legendscale_x_continuous(name ="Period", breaks =1:P)+scale_y_continuous(name ="Sales")+scale_color_discrete(labels =c("Control Group", "Treatment Group"))+guides(colour =guide_legend(reverse =T))+theme(legend.title =element_blank())+ggtitle("Scenario B\nEvent Study")
For treatment and control group, we see the same trend over time. This lends credibility to the parallel trends assumption and consequently, to the validity of the causal treatment effect.
Other than in scenario A, the parallel trends assumption does not seem to hold. The estimated treatment effect is larger than the actual treatment effect. This is due to different trends in both groups. The treatment group has a more positive trend even without treatment and the groups would have further diverged after treatment (see dashed red line). The difference between the dashed red and dashed blue line is attributable to this trend and should not be part of the treatment effect.
Modeling
A more typical situation is usually that there is more than one unit in the treatment and control group. You could e.g. imagine that you are managing more than two stores and are implementing an ad campaign in a specific region.
To simulate such a scenario, we generate data for 3’000 stores that are split evenly into two regions. In one region, the ad campaign will be run (treatment region) and in the other there will be no campaign (control region). The variable relationships as defined in the previous section still hold.
# [1.4] Linear regression ----# Now assume that there are more than two stores and treatment is performed# in a specific region which is, depending on scenario (A) and (B) # different to the control region.# Generate a bunch of samples and combine in one table. Here, we choose a higher# standard deviation.# We assume that we only have data from one period prior and one period after # treatment.n_stores<-3e+3# Scenario Adf_A_lm<-lapply(1:n_stores, function(R){generate_data(sd =1, scenario ="A")})%>%bind_rows()%>%filter(period%in%(P/2):(P/2+1))# Scenario Bdf_B_lm<-lapply(1:n_stores, function(R){generate_data(sd =1, scenario ="B")})%>%bind_rows()%>%filter(period%in%(P/2):(P/2+1))
Scenario A
So how do we compute the average treatment effect? Previously in this chapter, we just used basic math calculations (particularly subtraction). But there is an easier way: we can use regression again. This is because the average treatment effect is the coefficient of the interaction of group and time.
\(Time\) indicates whether the period is before or after the treatment and \(Treatment\) whether an observation belongs to the treatment group. We can interpret the estimated coefficient \(\hat\beta_1\) as the time effect for both groups, it indicates how the outcome evolves without treatment. \(\hat\beta_2\) represents the time-invariant level difference between groups, it is positive when the treatment group initially exhibited a higher outcome level.
What we are primarily interested in is the interaction \(Time \times Treatment\) and its estimate \(\hat\beta_3\). It is only active for the treatment group after the treatment (\(Time = 1\), \(Treatment=1\)) and represents the average treatment effect.
For scenario A, we can see that there is no need to adjust for the covariate \(x1\). You could for example think of \(x_1\) as the purchase power of the respective region. If you check the formulas again, your will notice that \(x1\) has a constant and time-invariant effect on sales and therefore it does not violate the parallel trends assumption.
Including or leaving out \(x1\) in the regression yields a very similar unbiased estimate (close to defined true size) for our variable of interest \(store:after\), the parameter of interest.
# [1.4.1] (A) ----# (a): Due to the construction of the data set, we expect interaction# coefficient to be significant as well as the covariate and period. However, as# the covariate does not have a time-varying effect, it is not a confounder and# interaction coefficient should be unbiased even if not adjusting for the# covariate.summary(lm(sales~treat*after , data =df_A_lm))
Call:
lm(formula = sales ~ treat * after, data = df_A_lm)
Residuals:
Min 1Q Median 3Q Max
-5.176 -0.952 0.002 0.956 6.392
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.9610 0.0257 1981.43 <2e-16 ***
treat 1.0372 0.0364 28.52 <2e-16 ***
after 0.2642 0.0364 7.26 4e-13 ***
treat:after 0.9813 0.0514 19.08 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.4 on 11996 degrees of freedom
Multiple R-squared: 0.284, Adjusted R-squared: 0.284
F-statistic: 1.58e+03 on 3 and 11996 DF, p-value: <2e-16
Call:
lm(formula = sales ~ treat * after + x1, data = df_A_lm)
Residuals:
Min 1Q Median 3Q Max
-3.947 -0.680 0.000 0.673 4.204
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 50.98128 0.01821 2800.25 <2e-16 ***
treat 0.03914 0.02732 1.43 0.15
after 0.22876 0.02575 8.88 <2e-16 ***
x1 0.98721 0.00903 109.31 <2e-16 ***
treat:after 0.97808 0.03641 26.86 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1 on 11995 degrees of freedom
Multiple R-squared: 0.641, Adjusted R-squared: 0.641
F-statistic: 5.36e+03 on 4 and 11995 DF, p-value: <2e-16
Scenario B
In scenario B, the effect of \(x_1\) is different because it has a time-varying effect. Therefore it violates the parallel trends assumption, leading to a biased estimate if \(x_1\) is not included (e.g. because it is unobserved).
Because we constructed the data set ourselves, we are able to see that the bias in fact is quite large and the treatment effect seems to include the actual treatment effect plus the effect of \(x_1\).
# [1.4.2] (B) ----# (b): Due to the construction of the data set, we expect interaction coefficient# to be significant and accurate only when adjusting for the time-varying effect# of the covariate and main effects for period and covariate.summary(lm(sales~treat*after, data =df_B_lm))
Call:
lm(formula = sales ~ treat * after, data = df_B_lm)
Residuals:
Min 1Q Median 3Q Max
-15.025 -2.331 0.008 2.293 16.433
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 51.0835 0.0643 794.08 <2e-16 ***
treat 3.6321 0.0910 39.92 <2e-16 ***
after 0.0682 0.0910 0.75 0.45
treat:after 1.4315 0.1287 11.13 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.5 on 11996 degrees of freedom
Multiple R-squared: 0.287, Adjusted R-squared: 0.287
F-statistic: 1.61e+03 on 3 and 11996 DF, p-value: <2e-16
Only with including \(x_1\) and as a main effect and moderator, we can reconstruct the true treatment effect.
# Including time-varying effectsummary(lm(sales~treat*after+after*x1+treat*x1, data =df_B_lm))# best
Call:
lm(formula = sales ~ treat * after + after * x1 + treat * x1,
data = df_B_lm)
Residuals:
Min 1Q Median 3Q Max
-4.084 -0.682 0.001 0.679 4.348
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 51.00199 0.01818 2804.68 < 2e-16 ***
treat 0.00336 0.03012 0.11 0.91
after 0.16597 0.02571 6.45 1.1e-10 ***
x1 2.63804 0.01591 165.81 < 2e-16 ***
treat:after 1.00018 0.04063 24.62 < 2e-16 ***
after:x1 0.36083 0.01823 19.80 < 2e-16 ***
treat:x1 1.03128 0.01823 56.57 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1 on 11993 degrees of freedom
Multiple R-squared: 0.943, Adjusted R-squared: 0.943
F-statistic: 3.31e+04 on 6 and 11993 DF, p-value: <2e-16
Conclusion
DiD is a useful quasi-experimental method that relies on the parallel trends assumption which is untestable. We can’t prove it but try to justify it by for example showing prior trends. If both groups were evolving similarly before the treatment, that supports the plausibility and appropriateness of using DiD.
DiD is a very actively researched methods and can be extended too many scenarios: e.g. the synthetic control method, that is able to deal with one treated and multiple untreated groups. By matching and weighting the untreated groups, a synthetic group is composed, that is similar in the lead up to the treatment period. It shares similarities with what we have done in the matching chapter. Sometimes you also might end up with many treatment groups and variation in treatment timing. Although you have to be careful with your assumptions and specifications, such cases can also be incorporated into a DiD framework.
Assignment
Imagine, you are manager of a large health provider that manages many hospitals and you want to test how a new admission procedure affects patient satisfaction. You randomly selected 18 hospitals that introduced the new admission procedure and compare them to 28 other hospitals that did not introduce the method. For both groups of hospitals you collected data from before and after the introduction. The data you have collected is from patient surveys where they were asked how satisfied they are.
Load the data from the file hospdd.rds1. Then, perform a difference-in-differences analysis by
Manually computing the mean satisfaction for treated and control hospitals before and after the treatment. Helpful functions could be filter(), pull() and basic arithmetic operations.
Using a linear regression to compute the estimate. Also, include group and time fixed effects in the regression, i.e. one regressor for each month and one regressor for each hospital: Consider, whether you want to include them as
month + hospital or as
as.factor(month) + as.factor(hospital)
and explain what the difference is.
How to submit your solutions!
Please see here how you have to successfully submit your solutions. I would recommend you to solve the assignments first in .R scripts and in the end convert them to the required format as explained in the submission instructions.