Before we dive into topics of causal inference, we review some basic concepts of probability and statistics. All methods that we will use later in this course are based on statistical models and these require probability theory. But we will keep it as short as possible as our focus and learning goal lies more on applications and coding than on the theoretical part.
Assignments
Please note: in this chapter, there are two assignments in between. In the other chapters, you’ll usually find the assignments at the end.
Probability
We will start by reviewing some basic concepts of probability theory, drawing probability trees, introducing set theory and applying Bayes theorem.
Basic rules of probability
Consider the most simple example: flipping coins. We define the outcome of the flip of a coin as a random variable as we are uncertain about what side the coin lands on. To express this uncertainty, we make us of probability theory.
After flipping the coin, we will see what side the coin has landed on and our random variable has taken on of the two possible events\(\{H, T\} \subseteq \Omega\). It will be either Head or Tail.
So we have already defined two terms: random variable and events. Now what is a probability? A probability is always linked to an event typically denoted by a capital letter, here either \(H\) and \(T\), and expresses how likely this event is to happen. Probabilities are always between 0 and 1 and for flipping the coin, as long as it is a fair coin (which we assume), the probabilities are
\[
P(H) = P(T) = 0.5
\]
Extreme cases: If an event \(A\) is impossible, its probability is \(P(A) = 0\) and if it is certain to occur, it is \(P(A)=1\).
Important
Axiom 1: Probability is a real number greater or equal to 0.
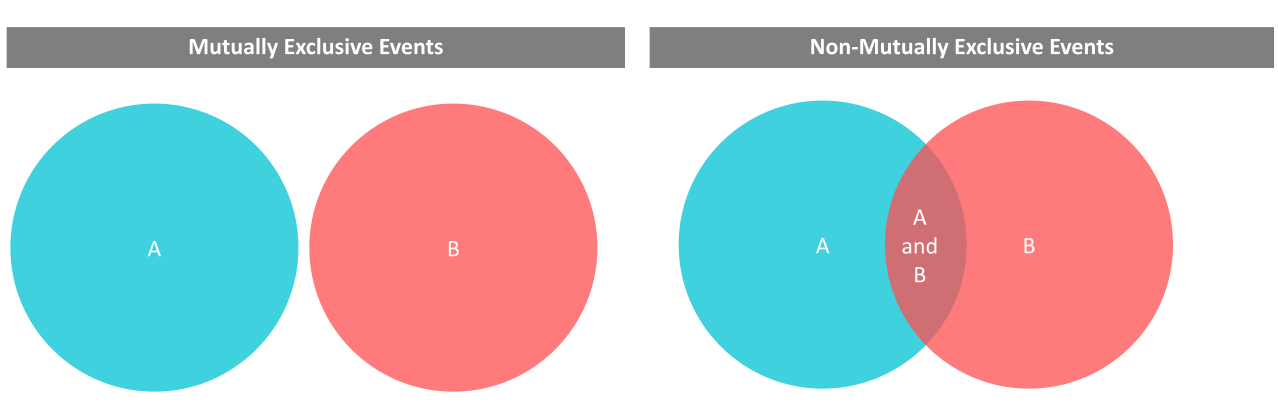
We can also introduce the compliment\(\overline{A}\), which is what happens when \(A\) does not happen and consequently, \(P(A) + P(\overline{A}) = 1\). \(A\) and \(\overline{A}\) are mutually exclusive, by definition. But there could also be two events \(A\) and \(B\) that are mutually exclusive, i.e. only one of those events can happen, then \(P(A \cup B) = P(A) + P(B)\), where \(\cup\) represents the union of both events. The probability of either event happening is equal to the sum of the individual probabilities. For example,
\[
P(H \cup T) = P(H) + P(T) = 1
\]
which shows two things, that the total probability is equal to 1 and that the probability of mutually exclusive events is the sum of the individual probabilities.
Important
Axiom 2: Total probability is equal to 1.
Important
Axiom 3: Probability of mutually exclusive events is the sum of the probabilities. (Mutually exclusive: events can’t happen at the same time)
To understand what not mutually exclusive events are, consider events \(studying\) and \(working\). For a random person, we don’t know what values these random variables take on. But we know the probability for the event that someone is studying or someone is working. And there are also individuals who do both or neither.
Then, the probability of at least one of the events happening is calculated by
\[
P(A \cup B) = P(A) + P(B) - P(A \cap B)
\]
with \(P(A \cap B)\) being the intersection of both events, i.e. the probability of both studying and working. This formula is based on the addition rule.
Tip
\(\cup\) : Union, can be translated as “or”.
\(\cap\) : Intersection, can be translated as “and”.
For mutually exclusive events:
\[
P(A \cup B) = P(A) + P(B) - P(A \cap B) = P(A) + P(B)
\]
The aforementioned intersection \(P(A \cap B)\) can be calculated by the multiplication rule,
\[
P(A \cap B) = P(A|B) * P(B) = P(B|A) * P(A)
\]
where \(P(A|B)\) denotes the probability of \(A\) happening given that \(B\) has happened. It is called a conditional probability and is defined by:
\[
P(A \mid B) = \frac{P(A \cap B)}{P(B)}
\]
It can be thought of as the probability of an event \(A\) after you know that \(B\) is true. Essentially, it computes the possibility of event \(A\) and \(B\), normalized by the probability of \(B\) occurring. The conditional probability is crucial when talking about causality which you will later see as it for example yields probabilities for specific groups.
Using the example with workers and students: without knowing exact numbers, we can assume that students are less likely to work than individuals who are not studying.
Essentially, we are looking at probabilities restricted to a subset of the sample, which in this comparison are the subsamples of studying persons and non-studying persons.
Another important concept when dealing with probabilities of events is stochastic independence. In case of two events being independent, the conditional probability is equal to the probability of the event happening anyways. Let’s think of rolling a die twice (first roll \(R_1\) and second roll \(R_2\)).
\[
P(R_2 \mid R_1) = P(R_2)
\]
The second roll does not depend on the first one. With each roll the outcomes \({1, 2, 3, 4, 5, 6}\) have the same probability likely independent of the previous roll. If we want to compute the probability of both rolls being a \(6\), we would just have to multiply the probabilities for each roll.
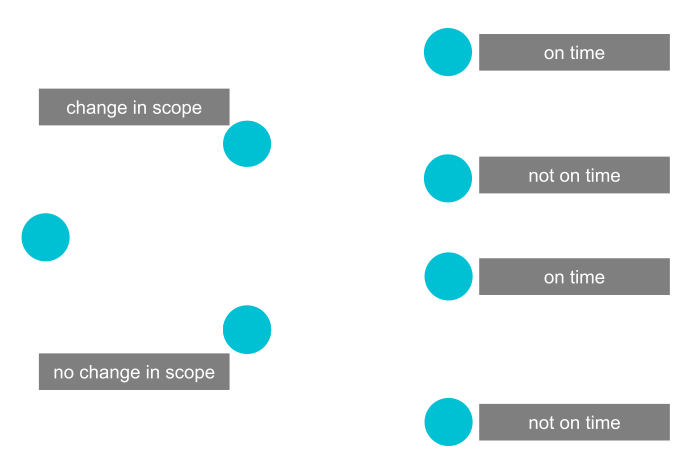
Let’s go back to the case where events are dependent on each other. An intuitive way to think about (conditional) probabilities is a probability tree. Branches from one node always sum to \(1\) in probability as one (and only one) of the events happens. The probability of two consecutive events is obtained by multiplying the probabilities.
Consider the following example: you are project manager and based on your are interested in the probability of a project being delivered on time. Based on your experience, you know that whether a project is on time depends on whether there is a change in scope. Using historical data about past projects, you come up with the following tree.
Assignment I
Define being on time as event \(T\), being not on time as \(\overline{T}\), having a change in scope as \(S\) and having no change in scope as \(\overline{S}\). (Hint: Check here, if you are not sure what is shown in the probability tree.)
Then, compute the following probabilities and the sum of all four probabilities.
\(P(T \cap S)\)
\(P(T \cap \overline{S})\)
\(P(\overline{T} \cap S)\)
\(P(\overline{T} \cap \overline{S})\)
Tip
With some browsers and specific operating systems, the compliment probability is not shown correctly (missing the horizontal bar above the letter). In that case it often helps to zoom in or out.
How to submit your solutions!
Please see here how you have to successfully submit your solutions. I would recommend you to solve the assignments first in .R scripts and in the end convert them to the required format as explained in the submission instructions.
Set Theory
Another useful tool to visualize the occurrence and relationship between events are Venn diagrams that are based on set theory. We already used a simple one above to illustrate the difference of mutually exclusive and non-mutually exclusive events.
Let’s use an example to understand some other rules mentioned above using a Venn diagram: suppose you are working in a company that has developed an application available on three different kind of devices: smartphones, tablets and computers. So far your pricing plan is very simple and you have just charged the same amount from all customers, regardless of what and how many devices they use.
But now you want to review your pricing plan and evaluate whether it could make sense to offer pricing plans that differ in the device and number of maximum devices that can be used per account. So first of all you collect usage data of a random sample of 1000 customers from the last month to get an idea of the current usage distribution.
Instead of using actual data, we simulate the data collection process here. If you are interested how to do it in R, you can expand and check out the code by clicking on Code. But you don’t have to. And don’t worry, if it looks too complicated at this point, just move on.
Note
library() loads external packages/libraries containing functions that are not built in base R.
tibble() is the most convenient way to create tablets. You specify column name and content and assign your tibble to an object to store it.
ifelse(test, yes, no) is a short function for if…else statements. The first argument is a condition that is either TRUE or FALSE and determines whether the second or third argument is returned.
rbinom(n, size, prob) samples n values from a binomial distribution of a given size and with given probabilities prob.
mutate() is one of the most important functions for data manipulation in tablets. It is used to either create or change variables/columns. You provide the column name (new or existing) and then specify how to create or change the values in that specific column. For example, mutate(table, new_variable = existing_var / 100), which is equivalent to table %>% mutate(new_variable = existing_var / 100).
Code
# Load tidyverse packagelibrary(tidyverse)# Number of obervationsn<-1000# Create tibbleapp_usage<-tibble(# Create user_id in increasing order user_id =1:n,# Randomly sample if smartphone was used smartphone =rbinom(n, 1, 0.4),# Sample if tablet was used. More likely if smartphone was not used. tablet =ifelse(smartphone==1, rbinom(n, 1, 0.2), rbinom(n, 1, 0.5)),# Sample if computer was used. More likely if tablet was not used. computer =ifelse(tablet==1, rbinom(n, 1, 0.1), rbinom(n, 1, 0.3)))# If no device has value of 1, we set smartphone to 1app_usage<-app_usage%>%rowwise()%>%mutate(smartphone =ifelse(sum(smartphone, tablet, computer)==0, 1, smartphone))
Here, we simulated some artificial data. Seeing the formulas used for constructing the data, we already know that e.g. customers tend not to use the app on both tablet and computer. Please note that \(1\) indicates usage and \(0\) indicates no usage.
Note
To see the first lines of a table (for example a tibble() or a data.frame(), you can use the head(table, n) function, where n specifies how many rows you want to see.
A general overview of total customers per device category shows that in the smartphone category there are the most users and in the computer category there are the least.
Note
Summing all values by column is done by colSums(table). To sum rows, you can use rowSums(table).
The sum of \(user\_id\) does not really tell us anything. We could ignore it, but we can also just access the columns we want to sum. There are several ways.
Note
To access only specified columns, you can provide the location or names in square brackets or you can use the select() function.
# Equivalent commands to select specific columns#colSums(app_usage[, 2:4])#colSums(app_usage[, c("smartphone", "tablet", "computer")])app_usage%>%select(smartphone, tablet, computer)%>%colSums()
smartphone tablet computer
589 389 226
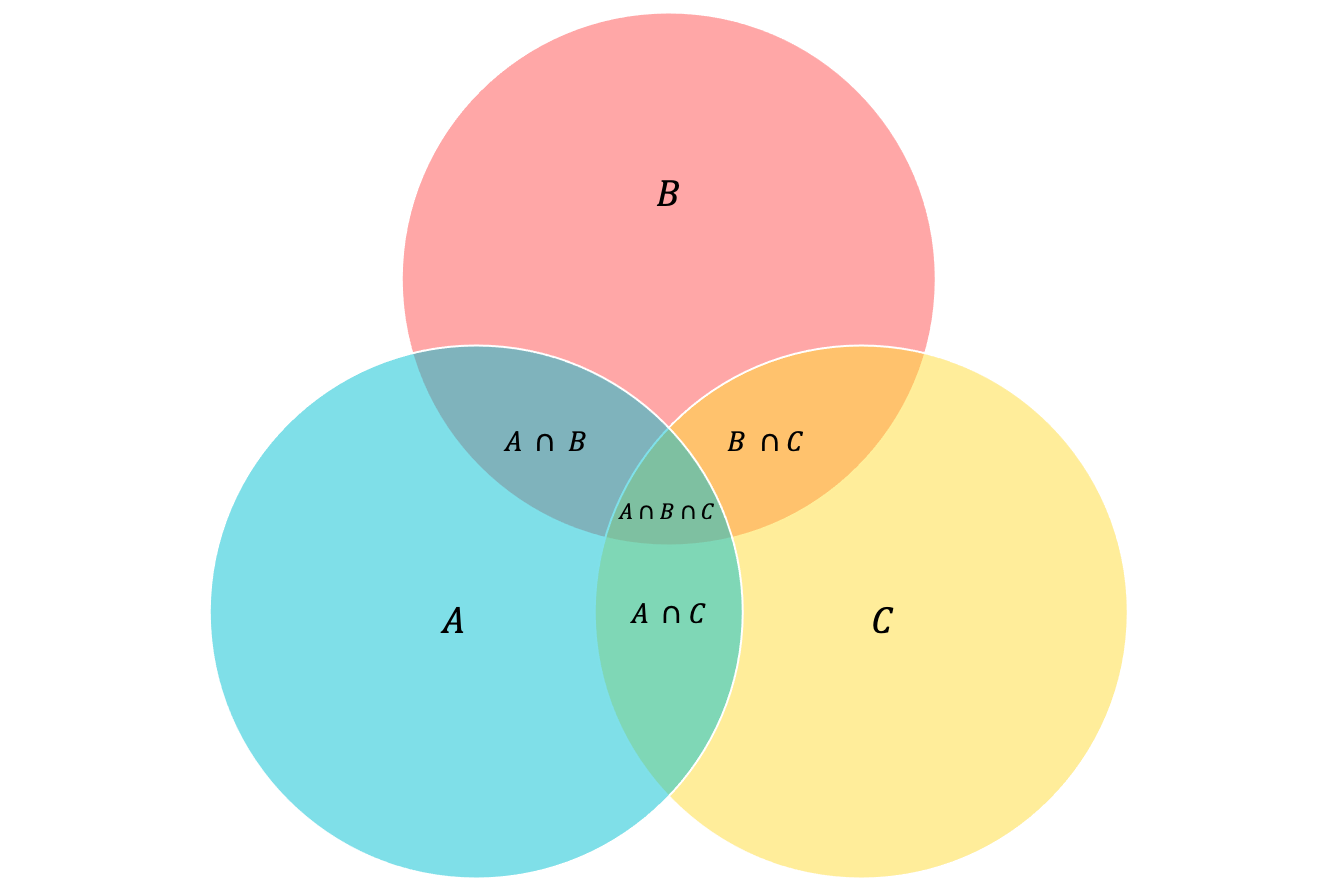
Now let’s see what the Venn diagram says, which is a diagram showing the relation between sets. We can see the union, intersection differences and complements in the diagram.
Generic Venn diagram
Note
which() checks a condition and returns the indices.
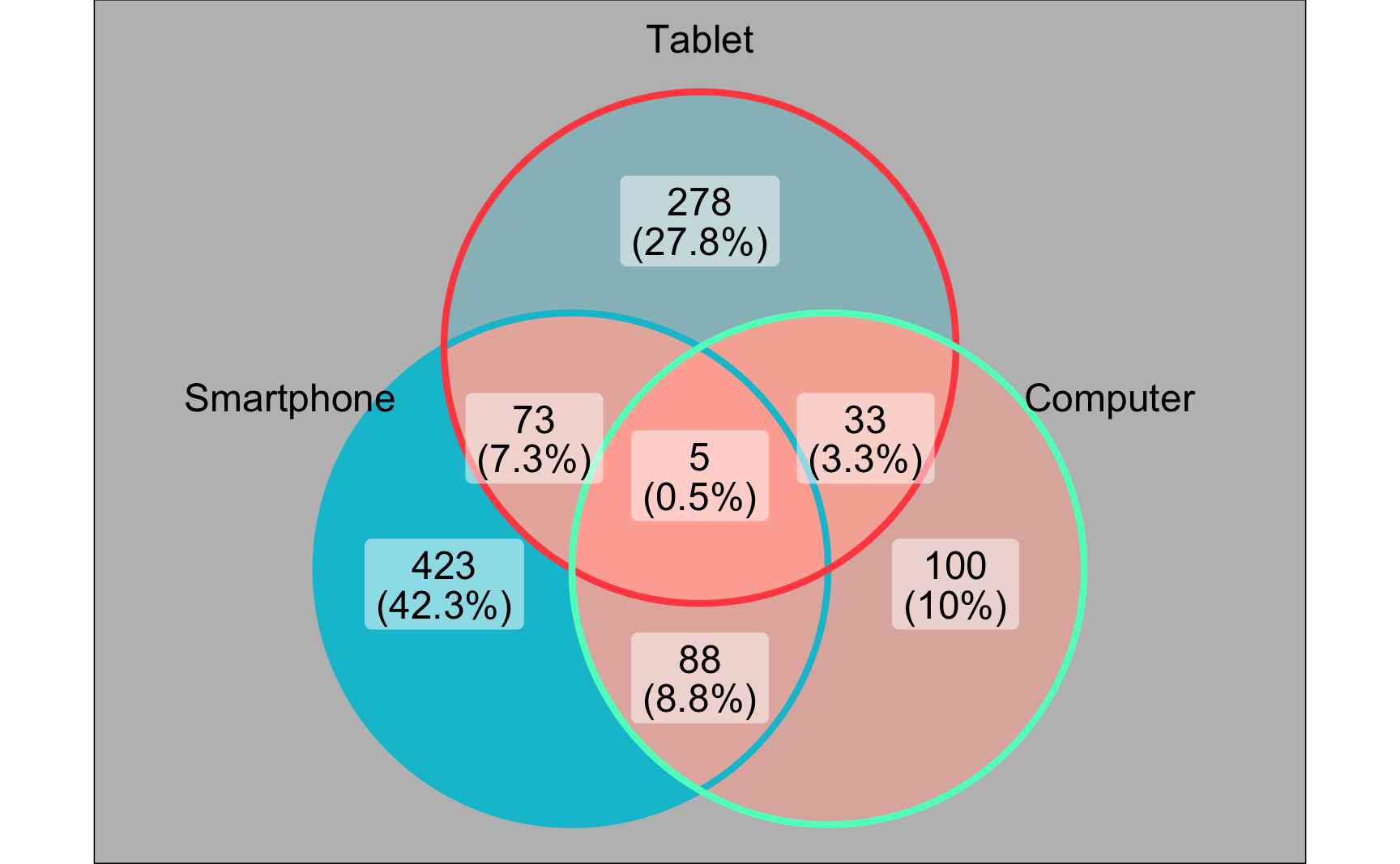
# Set of phone, tablet and computer usersset_phon<-which(app_usage$smartphone==1)set_tabl<-which(app_usage$tablet==1)set_comp<-which(app_usage$computer==1)# List of all setssets_all<-list(set_phon, set_tabl, set_comp)# Load additional package for plotting Venn diagramslibrary(ggVennDiagram)# Plot Venn diagramggVennDiagram(sets_all, category.names =c("Smartphone", "Tablet", "Computer"), label_percent_digit =2)+# Customizing appearancetheme(legend.position ="none", panel.background =element_rect("grey"), strip.background =element_rect("grey"))+scale_x_continuous(expand =expansion(mult =.24))
Assignment II
Using the Venn diagram above, answer the following questions.
What is the percentage of customers using all three devices?
What is the percentage of customers using at least two devices?
What is the percentage of customers using only one device?
How to submit your solutions!
Please see here how you have to successfully submit your solutions. I would recommend you to solve the assignments first in .R scripts and in the end convert them to the required format as explained in the submission instructions.
You can also use the example to go through the basic probability rules defined above (that does not belong to the assignment anymore).
Addition rule:
What is the percentage of customers using a smartphone, a tablet or both devices?
\(P(T \cup S) = P(T) + P(S) - P(T \cap S)\)
Multiplication rule:
Given that a customer uses a computer, how likely is he/she to use a tablet as well?
\(P(T|C) = \frac{P(T \cap C)}{P(C)}\)
Total probability rule:
What is the fraction of customers using a computer?
\(P(C) = P(C \cap T) + P(C \cap \overline{T})\)
Bayes Theorem
Math
A very important theorem in probability theory is Bayes theorem. In fact, it has been called the most powerful rule of probability and statistics. Let’s quickly go through the math. By reformulating the multiplication rule
\[
P(A ∩ B) = P(A|B)*P(B) \\
P(B ∩ A) = P(B|A)*P(A)
\]
and using the equality of \(P(A ∩ B)\) and \(P(B ∩ A)\) we arrive at
Bayes theorem expresses a conditional probability, exemplary the likelihood of \(A\) occurring conditioned on \(B\) having happened before. With the Bayes theorem you can answer questions like:
How likely is it that it will rain, when there are clouds in the morning?
How likely is it that an email is spam if certain keywords appear?
Tip
You will often hear Bayes theorem in connection with the terms updating beliefs. You start with a prior probability \(P(A)\) and collecting evidence \(P(B)\) and the likelihood \(P(B|A)\), you update your prior probability to get a posterior probability \(P(A|B)\). That is in fact the foundation of Bayesian inference. Look it up if you want, but you won’t need Bayesian inference for this course.
To understand how useful Bayes theorem is, let’s use an example: Imagine, you are quality assurance manager and you want to buy a new tool that automates part of the quality assurance. If the tool finds a product it considers faulty, an alarm is triggered. The seller of the tool states that if a product is faulty, the tool is 97% reliable and if the product is flawless, the test is 99% reliable. Also, from your past experience you know that 4% of your products come out with flaws.
To assess the usefulness of the tool in practice you want to know the following probabilities:
What is the probability that when the alarm is triggered the product is found to be flawless?
What is the probability that when the alarm is triggered the product is found to have flaws?
Using Bayes theorem and the formulas will help you to arrive at the correct answers and guide your decision whether to buy the tool.
We should start by defining the events and event sets:
\(A\): product is faulty vs. \(\overline{A}\): product is flawless
\(B\): alarm is triggered vs. \(\overline{B}\): no alarm
Also, from our past experience and the producers specifications we already know some probabilities:
\(P(B|A) = 0.97\)
\(P(B|\overline{A}) = 0.01\)
\(P(A) = 0.04\)
Note, that what we are looking for is not the same as what the manufacturer states in his/her specifications. What we are looking for is \(P(\overline{A}|B)\) (1) and \(P(A|B)\) (2) and we will need Bayes theorem to obtain those probabilities.
These results show that in case the alarm is triggered, there is a possibility of about __% that the product is flawless and a probability of __% that the product is faulty.
How to submit your solutions!
Please see here how you have to successfully submit your solutions. I would recommend you to solve the assignments first in .R scripts and in the end convert them to the required format as explained in the submission instructions.
{kind=link}